告别显卡“绑架”,让算力真正为业务所用
在AI算力军备竞赛愈演愈烈的今天,无论是大模型训练还是推理应用,算力底座的自主可控已成为企业关注的焦点。很多企业面临一个尴尬的现状:机房中不仅有昂贵的NVIDIA A100/H100,还有性价比突出的AMD Instinct系列,甚至还有逐渐成熟的华为昇腾、海光DCU等国产芯片。
然而,传统的算力调度方式往往让企业深陷“厂商绑定”的泥潭——NVIDIA 的 K8s 插件(DCGM/Device Plugin)只能管 NVIDIA,AMD 的 ROCm 环境又是一套独立的生态。如何将这些“异构算力”整合到一个平台中,让上层应用像用水用电一样按需调用?
本文将手把手教你搭建一套基于 Kubernetes 的异构算力统一管理平台,彻底摆脱单一厂商的锁定。
一、为什么要构建异构算力平台?
在开始技术选型之前,我们需要明确异构算力平台的三大核心价值:
- 成本优化:并非所有任务都需要 H100 的高带宽。推理任务可以跑在国产卡或 AMD 卡上,训练任务跑在旗舰卡上,实现成本与性能的最佳平衡。
- 供应链安全:单一厂商的供货周期和价格波动极大。支持异构芯片意味着在关键时刻,哪家卡有货、价格合适,就采购哪家,掌握采购主动权。
- 资源利用率提升:通过统一调度,将原本孤立的“显卡资源池”融合,消除资源碎片。
二、核心架构:统一抽象层
要实现异构算力的统一管理,关键在于“抽
下图展示了平台的逻辑架构。我们构建了一个统一的调度层,对下屏蔽硬件差异,对上提供标准的 K8s API 接口。
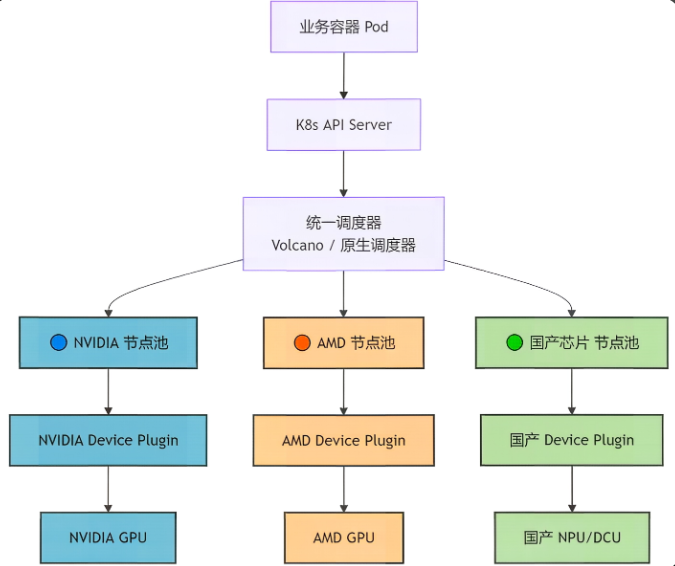
说明:
- NVIDIA 设备插件及 GPU 资源,上报 nvidia.com/gpu
- AMD 设备插件及 GPU 资源,上报 amd.com/gpu
- 国产芯片设备插件及 NPU/DCU 资源,上报厂商自定义资源名(如 huawei.com/ascend)
三、关键步骤:搭建异构集群
3.1 基础设施准备
首先,你需要准备一批服务器,分别安装好不同厂商的显卡,并确保操作系统(建议 Ubuntu 20.04/22.04)和内核版本统一。
- NVIDIA 节点:安装 NVIDIA 驱动(≥525.60.11)和 nvidia-container-toolkit。
- AMD 节点:安装 ROCm 驱动和 amd-gpu 工具包。
- 国产芯片节点:安装厂商提供的专有驱动(如华为昇腾的 npu-driver)。
3.2 设备插件的部署与配置
Kubernetes 本身并不知道显卡是什么,需要通过 Device Plugin 将硬件资源作为 Extended Resource 上报给 API Server。
核心配置要点:
在部署 K8s 集群后,我们需要分别部署对应的插件。为了让调度器能够识别差异,我们需要为不同厂商的节点打上特定的 Label(标签)。
# 为节点打标签,区分厂商
kubectl label nodes node-nvidia-01 gpu-vendor=nvidia
kubectl label nodes node-amd-01 gpu-vendor=amd
kubectl label nodes node-camb-01 gpu-vendor=cambricon
3.3 统一调度策略的落地
仅仅让资源上报是不够的,如果调度器不感知拓扑和性能差异,可能会导致“大材小用”或“跨卡通信失败”。我们需要引入更高级的调度器,例如 Volcano(开源高性能调度引擎)。
实施策略:
- 节点亲和性:通过 nodeSelector 或 nodeAffinity,让需要显存大、算力强的训练任务优先调度到 NVIDIA 旗舰卡节点;让轻量级推理任务调度到国产卡或 AMD 节点。
- 资源共享与隔离:对于不支持切分的国产芯片,利用 Volcano 的 binpack 策略,将碎片化的资源尽可能打包利用。
四、直面挑战:国产芯片的适配难点
在搭建异构平台时,最大的痛点往往不在 NVIDIA 和 AMD,而在于国产芯片的适配。主要体现在以下三个方面:
4.1 算子生态差异
NVIDIA 有成熟的 CUDA 生态,而国产芯片通常需要重新编译算子。在 K8s 层面,我们需要通过 镜
4.2 监控可观测性
NVIDIA 有 DCGM Exporter 提供精细化的 GPU 监控。国产芯片的监控接口往往不统一。解决方案是在平台层统一抽象出 Metrics 标准,通过自定义 Exporter 将国产芯片的监控数据转换成 Prometheus 标准格式。
4.3 拓扑感知
多卡训练时,NVIDIA 支持 NVLink,AMD 支持 Infi
五、实战:部署一个异构训练任务
假设我们有一个 PyTorch 训练任务,希望在资源充足时优先使用 NVIDIA 卡,降级时使用国产卡。我们可以通过 Volcano 的 Job 配合 nodeSelector 来实现。
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: mixed-training-job
spec:
schedulerName: volcano
tasks:
- name: nvidia-task
replicas: 4
template:
spec:
nodeSelector:
gpu-vendor: nvidia # 优先调度到蓝色标记节点
containers:
- name: trainer
image: pytorch/pytorch:latest
resources:
limits:
nvidia.com/gpu: 1
- name: china-task
replicas: 2
template:
spec:
nodeSelector:
gpu-vendor: cambricon # 降级调度到绿色标记节点
containers:
- name: trainer
image: pytorch/pytorch-cambricon:latest
resources:
limits:
cambricon.com/mlu: 1六、调度决策的完整流程
为了更直观地理解整个调度过程,我们绘制了第三张图——调度决策全流程图。这张图展示了从一个 AI 任务提交到最终在具体芯片上运行的完整链路。

七、未来展望:从“版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! 能用”到“好用”
搭建好异构算力平台只是第一步。为了让平台真正“好用”,我们还需要在以下方面持续演进:
7.1 智能画像
建立 AI 任务的历史性能数据库,自动推荐最适合该模型结构的芯片类型。
7.2 成本中心
引入 FinOps 理念,为不同的芯片设置不同的“计费权重”,让业务部门直观地看到使用国产卡带来的成本节约,从而推动迁移。
7.3 统一存储
异构训练最大的痛点是数据同步。需要构建基于 JuiceFS 或 Alluxio 的统一数据加速层,确保无论任务调度到哪张卡上,都能秒级加载训练数据。
八、总结
“不再被厂商绑定”不是一句口号,而是一套落地的技术架构。通过 Kubernetes 强大的扩展能力,结合 Volcano 等高级调度引擎,我们完全有能力将 NVIDIA、AMD 和国产芯片纳入统一的管理体系。
这套异构算力平台的搭建,不仅保障了企业 AI 基础设施的供应链安全,更将算力的选择权真正交还给了业务方。在未来的算力竞争中,能够灵活调度一切可用芯片的企业,才能真正实现降本增效,掌握主动权。