在 2026 年的 AI 工程化领域,构建一个大模型应用早已不再是单纯的“炼丹”。随着模型参数量的持续膨胀和业务场景的复杂化,如何将数据预处理、监督微调(SFT)、强化学习人类反馈(RLHF)串联成一个稳定、可观测、可重试的自动化流水线,成为了衡量一个团队工程化能力的关键指标。
传统的 Bash 脚本和简单的 Python 调度器在面对 TB 级别的数据清洗、跨节点的分布式训练以及复杂的 RL
本文将手把手带你构建一套完整的 AI 工作流,从原始日志数据到最终对齐的 RLHF 模型。
一、 为什么选择 Argo Workflows?
在 2026 年的技术栈中,Argo Workflows 早已超越了简单的 CI/CD 范畴。对于 AI 场景,它具备三大核心优势:
- 声明式 DAG:AI 流程天然存在依赖关系(如:只有清洗完数据才能开始训练)。Argo 允许我们以 DAG 形式定义任务,最大化并发执行无依赖的步骤(例如同时处理多个数据分片),极大地节省了计算资源。
- 基于 Kubernetes 的资源管理:每个步骤都是一个独立的 Pod。对于数据预处理,我们可以分配 32核 CPU;对于 RLHF 的奖励模型推理,我们可以挂载 A100 GPU。资源隔离完美避免了环境冲突。
- 大规模重试与恢复:AI 训练极易因 OOM(内存溢出)或网络抖动失败。Argo 的自动重试机制和工件(Artifact)传递,允许流程从失败的 Step 恢复,而非从头开始。
二、 全链路架构概览
我们将整个 AI 工作流分为三大阶段:
- 数据工程阶段 —— 强调高吞吐、CPU密集型。
- 模型训练与对齐阶段 —— 强调 GPU 密集型、分布式协同。
- 评估与发
版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! 布阶段 —— 强调模型验证、质量门禁。
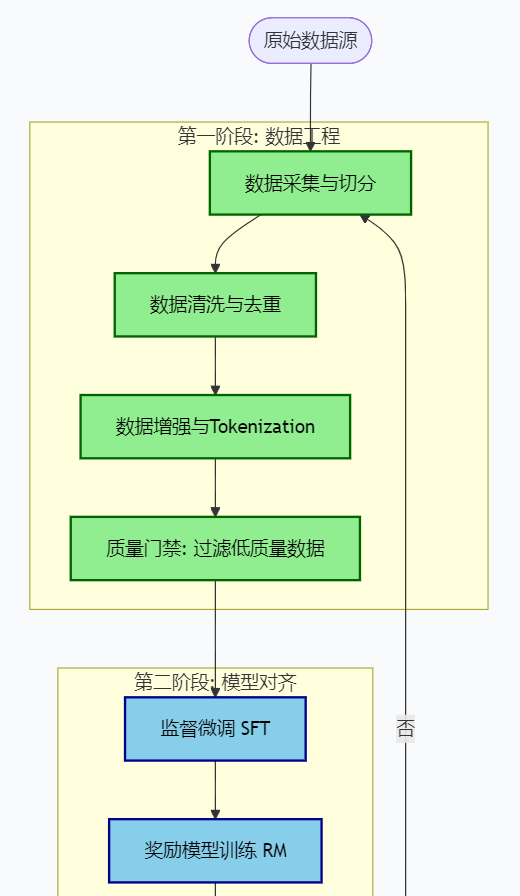

说明:
- 展示了数据处理的复杂性:不仅是清洗,还包括了基于模型的质量打分(门禁),确保“垃圾进,垃圾出”成为历史。
- 展示了从SFT到 RLHF 的演进。在 2026 年,单纯的 SFT 已无法满足复杂指令遵循需求,RLHF 成为标准步骤。
- 强调了发布前的自动化红队测试,如果评测分数不达标,工作流将自动回退到数据预处理阶段,形成数据飞轮闭环。
三、 实战拆解:Argo Workflows 核心步骤实现
让我们深入具体的 Argo 模板定义,看看如何将上述流程转化为可执行的 YAML。
3.1 数据预处理:分布式并行处理
在 2026 年,数据量通常以 TB 计。我们利用 Argo 的 DAG 和 parallelism 特性,启动数百个 Pod 并行处理数据分片。
3.1.1 核心逻辑
使用 input artifacts 挂载 S3 上的原始数据,

3.1.2 技术亮点
- 动态 DAG:Argo 支持动态任务生成,根据输入数据的分片数量,自动生成对应数量的 Worker Pod。
- 存储抽象:利用 Kubernetes PVC 或 S3 作为 Artifact Repository,数据在步骤间零拷贝传递,只传递路径索引。
3.2 模型训练与 RLHF:有向无环图调度
RLHF 是 AI 工作流中最复杂的部分,涉及四个模型(Actor、Reference、Critic、Reward)的协同。利用 Argo 的 steps 或嵌套 DAG,我们可以清晰地定义执行顺序,并在失败时快速重试。
3.2.1 核心逻辑
SFT 完成后触发 Reward Model 训练;两者都成功后,才能启动 RLHF 训练。
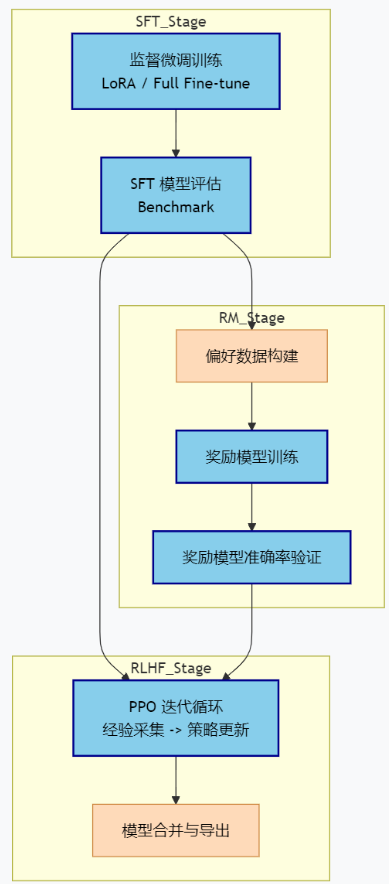
3.2.2 为什么这是 Argo 的强项?
在 2026 年,RLHF 的 PPO 阶段通常需要运行数十个迭代轮次。Argo 的 retryStrategy 可以精确捕获训练中的 OOM 错误,自动重启 Worker 而不影响整体流程。同时,artifactGC 策略可以自动清理中间产物,防止 K8s 集群的 etcd 被海量日志撑爆。
3.3 评估与发布:基于指标的条件分支
这是全链路的最后一道关卡。我们不再依赖人工肉眼查看 loss 曲线,而是引入自动化的红队测试和客观评测。
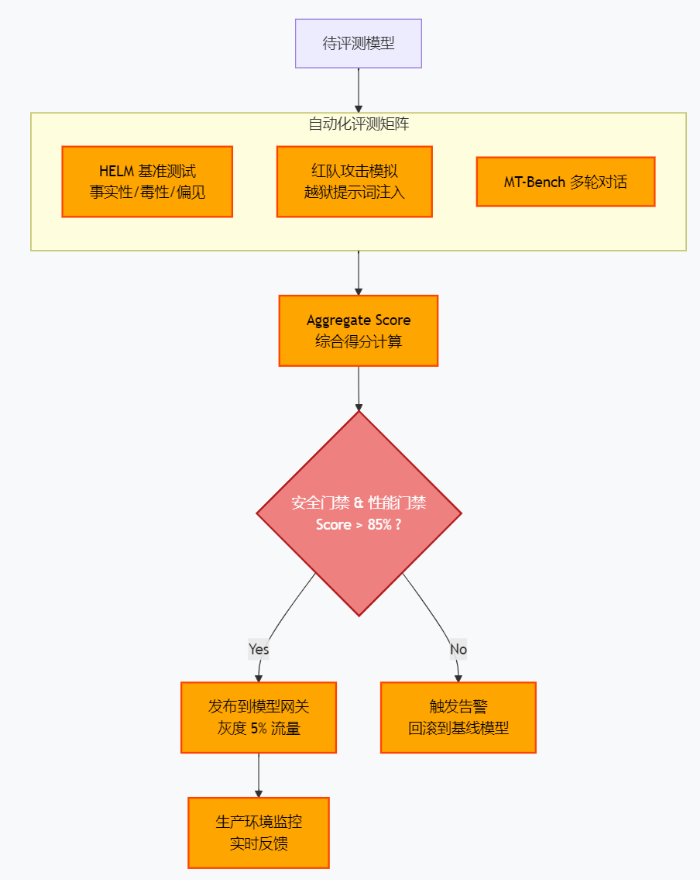
门禁机制: 在 Argo 中,我们利用 when 条件实现此逻辑。例如:
- name: release
template: release-model
when: "{{steps.score.outputs.parameters.score}} > 85"四、 总结:AI 工程化的未来
在 2026 年,AI 应用的竞争已经演变为 “数据质量 + 工程效率” 的竞争。通过 Argo Workflows 与 Kubernetes 的深度结合,我们成功地将过去需要数周才能跑
这套编排方案带来的核心价值在于:
- 可观测性:在 Argo UI 上,你可以一目了然地看到 RLHF 的每一步是卡在数据清洗,还是卡在奖励模型收敛。
- 成本控制:利用 K8s 的弹性,数据处理阶段使用 Spot 实例降低成本,训练阶段使用预留 GPU 实例保证稳定性。
- 可复现性:整个工作流以代码(YAML)形式存在,确保了从开发环境到生产环境的零差异迁移。
随着 AI Agent 技术的发展,未来的 Argo Workflows 将不仅仅是编排“任务”,更是编排“智能体”。但无论技术如何演进,结构化的流程控制与云原生基础设施的结合,始终是构建可靠 AI 系统的基石。