别再为了一个轻量级 API 烧掉整张 A100,那样你的 CFO 会哭的。“为了上线一个新模型,我们又要采购 5 张 A100。” “等等,这个模型推理只需要 2GB 显存和 10% 算力,用整卡不是血亏吗?”
这是 2025 年很多 AI 团队的日常。大模型训练固然需要“牛刀”,但大量推理场景——尤其是轻量级模型、微服务化 API——完全不需要独占整张 GPU。 今天,我们就来聊聊如何在 Kubernetes 上,通过 GPU 切分技术,让一张卡同时跑 10 个甚至更多推理服务,真正做到“杀鸡用菜刀,省下买牛刀的钱”。
一、场景与痛点版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! :为什么必须切分?
1.1 推理浪费场景
在推理场景中,我们常遇到三类“浪费”:
- 显存浪费:一个小 BERT 模型只需 2GB 显存,而一张 A100 有 80GB,闲置率高达 97.5%。
- 算力浪费:推理时 GPU 计算单元往往只在请求到来时短暂忙碌,大量时间空转。
- 调度僵化:传统方式下,一个 Pod 只能占用一整个 GPU,导致集群中碎片化严重,新服务无卡可用。
1.2 解决方案
在 K8s 上利用 GPU 切分技术,将一张物理 GPU 切割成多个逻辑 GPU,每个推理服务独享一小块显存和算力,互不干扰,从而实现高密度部署。
下面我们用流程图,分别展示架构、调度流程、监控调优三个维度,手把手教你搭建这套系统。
二、单卡多推理服务共享架构图
这个展示整体架构:K8s 集群中一个 GPU 节点,如何通过 Device Plugin 上报多个 GPU 资源,并让多个 Pod 共享同一张物理卡。
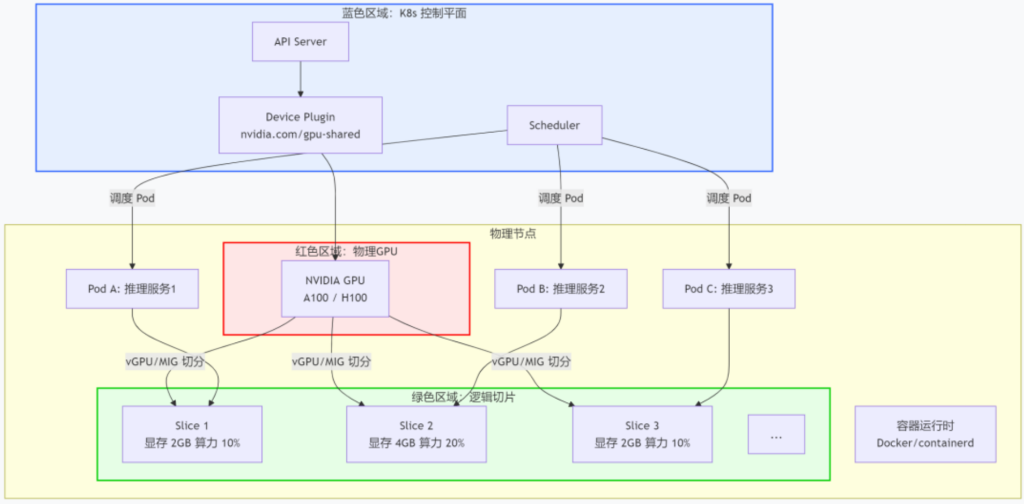
说明:
- K8s 控制平面:Device Plugin 上报自定义资源(如 nvidia.com/gpu-shared),Scheduler 根据资源请求调度 Pod。
- 物理 GPU:底层物理卡,通过 vGPU 或 MIG 技术切分为多个逻辑实例。
- 逻辑切片:每个切片对应一组显存和算力配额,供一个 Pod 独占使用。
关键点:切片数量和规格由管理员在节点上预定义,或通过 vGPU 调度器动态分配。2025 年主流方案支持 1% 算力步长和 MB 级显存切割。
三、服务部署与流量分发流程图
3.1 流程图
这个图展示从业务部署到请求路由的完整流程,强调如何将不同推理服务的流量正确分发到对应的 Pod。
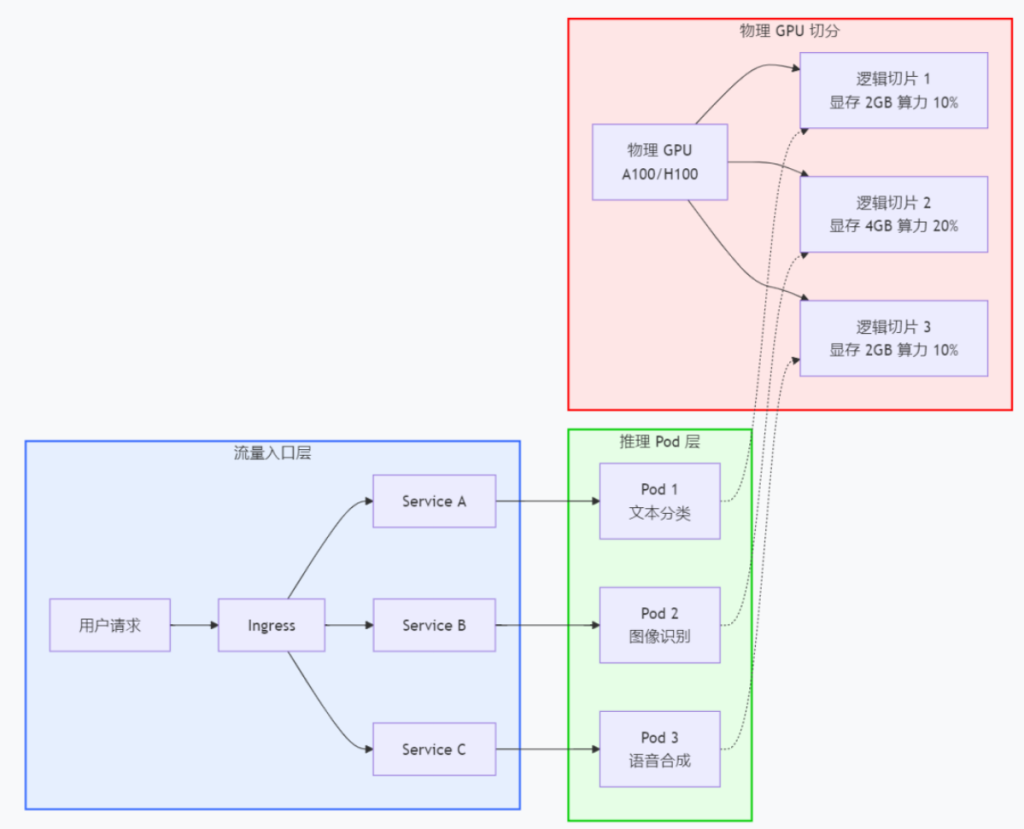
说明:
- 流量入口:Ingress 根据域名或路径将请求分发到不同 Service,每个 Service 后端对应一组同类推理 Pod。
- 推理 Pod 集):每个 Pod 请求一个逻辑 GPU 资源(如 nvidia.com/gpu-shared: 1),通过资源限制保证隔离。
- GPU 资源池:底层物理卡被切分为多个逻辑单元,Pod 与逻辑单元一一绑定。
3.2 关键实践
- 使用 NVIDIA Triton Inference Server 或 KServe 可以简化多模型部署,但底层依然需要 GPU
版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! 切分来共享卡。 - 每个 Pod 的 CPU/内存配额要匹配 GPU 切分大小,避免 CPU 成为瓶颈。
四、性能监控与动态调整流程图
4.1 性能监控流程图
这个图聚焦运行时监控与弹性伸缩,确保在高峰期能动态调整切分配额,避免服务相互影响。
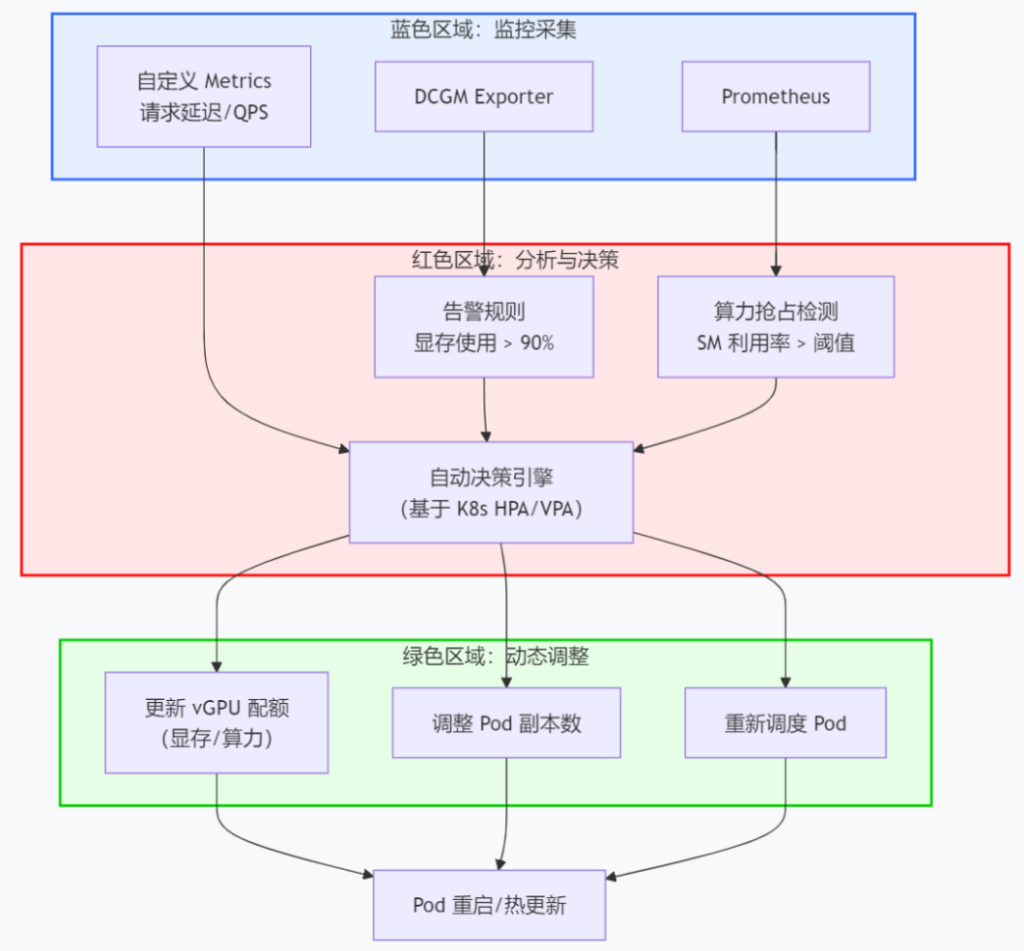
说明:
- 监控采集:DCGM Exporter 采集 GPU 指标,Prometheus 聚合,同时采集业务指标(如 QPS、延迟)。
- 分析决策:根据预设阈值判断是否需要调整。例如某个
版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! Pod 显存占用超过 90%,或算力抢占严重,触发调整。 - 执行调整:通过自定义控制器或 K8s HPA/VPA 修改资源配额、调整 Pod 数量或重新调度。
4.2 核心要点
- 2025 年主流的 vGPU 方案支持动态调整显存和算力配额(需重启 Pod 或支持热更新)。
- 配合 KEDA 基于 GPU 指标做弹性伸缩,可以在流量低谷时缩容 Pod,释放 GPU 切片供其他服务使用。
五、实战配置清单与最佳实践
最后,给出一份可直接套用的配置清单,助你快速落地。
5.1 选择切分方案
MIG(仅 A100/H100):适合严格隔离,切分粒度粗(最多 7 片),推荐用于大模型推理。
vGPU(所有 NVIDIA 卡):灵活微切割,推荐用于轻量级、多租户推理场景。
5.2 部署 Device Plugin
以 vGPU 为例(使用开源方案如 vgpu-device-plugin):
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: vgpu-device-plugin
spec:
template:
spec:
containers:
- name: vgpu-device-plugin
image: vgpu/device-plugin:latest
env:
- name: VGPU_ENABLE
value:"true"
- name: VGPU_MEMORY_STRATEGY
value:"dynamic" # 动态分配显存5.3 版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! Pod 使用切分资源
apiVersion: v1
kind: Pod
metadata:
name: inference-bert
spec:
containers:
- name: bert
image: my-inference-image
resources:
limits:
nvidia.com/gpu-shared: 1 # 请求一个逻辑 GPU
nvidia.com/gpu-memory:"2048"# 显存限制 2GB
nvidia.com/gpu-compute:"10" # 算力限制 10%5.4 调度优化
设置 CPU Manager 静态策略 + Topology Manager 单 NUMA 节点,避免跨 NUMA 延迟。
使用 Pod 亲和性 将同一类推理服务调度到同一节点,减少碎片。
5.5 监控与告警
部署 DCGM Exporter,重点关注 DCGM_FI_DEV_GPU_UTIL(GPU 利用率)和 DCGM_FI_DEV_FB_USED(显存使用)。
在 Prometheus 中配置规则,当某个逻辑 GPU 显存使用超过 80% 时,触发 HPA 增加 Pod 副本数。
六、总结
“杀鸡用牛刀”在过去或许是因为技术限制,但在 2025 年,我们有成熟的 GPU 切分技术和 Kubernetes 生态,完全可以让一张卡承载十个甚至更多推理服务。这不仅节省了硬件成本,还提升了资源利用率,让集群调度更加灵活。
从今天起,别再让一张昂贵的 A100 只服务一