“我们 8 张 A100,跑模型 GPU 利用率死活上不去,一直在 30% 左右晃悠,领导快疯了!”
这场景,你一定不陌生。2025 年,算力成本依然高企,企业纷纷从“拼卡量”转向“抠利用率”。在 Kubernetes
版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! 环境下,GPU 切分技术——无论是 NVIDIA 原生的 MIG,还是各种 vGPU 方案——成了救星。但理想很丰满,现实很骨感。切分后,利用率 30% 的魔咒反而更常出现了。今天,我们就来
版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! 一份 2025 年最新版的终极避坑指南,帮你把 GPU 的每一滴性能都榨出来。
一、为什么是 30%?罪魁祸首在哪里
在谈解决方案前,我们先诊断病因。GPU 利用率(通常指 nvidia-smi 中的 GPU-Util)卡在 30%,在 K8s 切分环境下,99% 是以下三个原因之一:
- 显存带宽瓶颈:切分后,算力核心虽多,但显存带宽是物理上限。小 batch size 下,计算单元在“等数据”。
- CPU 喂不饱 GPU:K8s 的 CPU 分配、节点亲和性没配好,DataLoader 成了木桶最短的那块板。
- 切分策略错误:MIG 切太碎,或者 vGPU 调度策略不当,导致物理 GPU 在“空转”。
下面我们用资源映射、调度策略、稳定性排障,手把手教你破局。
二、MIG vs vGPU 切分逻辑对比图
我们对比两种主流切分方案的内在逻辑。这是你选择技术路线的第一步,走错了,后面全白费
2.1 逻辑图对比
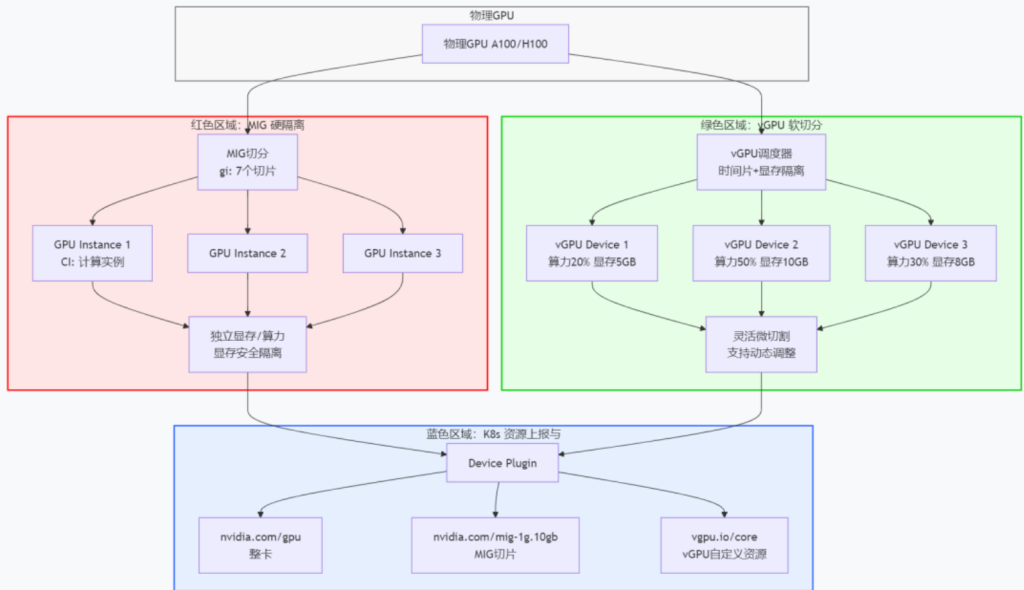
说明:
- MIG 硬隔离:物理级切分,显存绝对安全,适合大模型推理,但切分粒度粗(A100 最多 7 片),无法动态调整。
- vGPU 软切分:软件级时间片隔离,支持 1% 算力步长、MB 级显存微切割,适合微调与灵活混布,但需关注“吵闹邻居”。
- K8s 调度层:通过 Device Plugin 将不同切分资源上报为扩展资源,调度时需配合 Node Feature Discovery 识别拓扑。
2.2 避坑点
- 如果跑大模型推理,优先选 MIG(前提是卡型支持,如 A100/H100)。
- 如果跑微调或小 batch 训练,选 vGPU 并开启贪心调度模式。
- 千万别在 RTX 4090 上硬开 MIG,2025 年驱动虽能识别,但性能会跌到 10% 以下。
三、K8s GPU 切分调度全链路流程图
3.1 全链路流程图
确定了切分方案,下一步是调度。为什么利用率低?因为 Pod 没被调度到正确的“切分片”上,或者 CPU 与 GPU 没对齐。
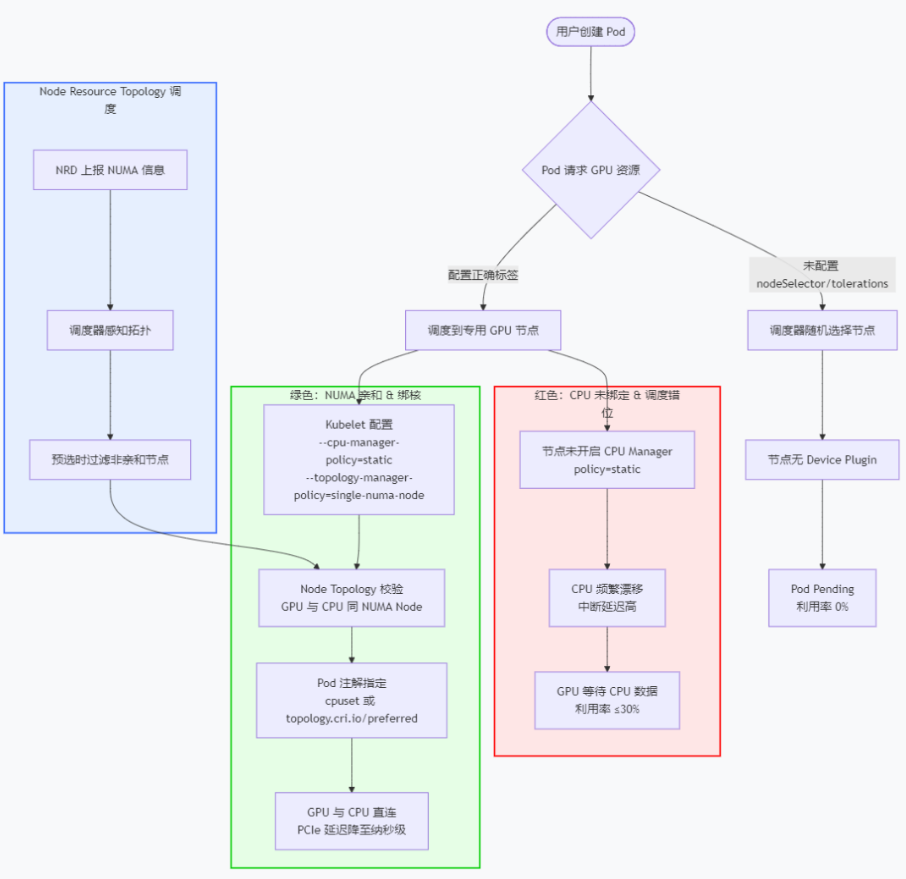
说明:
- 失败:Pod 虽调度到 GPU 节点,但未开启 CPU Manager 静态策略,CPU 跨核心漂移,中断处理延迟导致 GPU 饥饿,利用率卡在 30% 以下。
- 成功:开启 CPU Manager + Topology Manager 并配置 single-numa-node,强制 GPU 与 CPU 在同一 NUMA 节点,PCIe 延迟从微秒级降到纳秒级。
- 2025 年 K8s 原生支持 Node Resource Topology,调度阶段就检查 NUMA 亲和性,避免启动后才发现“跑偏”。
3.2 避坑点
- 必须开启 CPU Manager 和 Topology Manager,且设置 –cpu-manager-p
版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! olicy=static、–topology-manager-policy=single-numa-node。 - 检查 DataLoader 的 worker 数量。如果数据在远端,网络 I/O 会吃满 CPU,建议将数据集预加载到 NVMe 本地盘或使用 GPUDirect Storage。
四、GPU 利用率 30% 问题排查决策树
当你发现利用率不对劲时,不要慌,按照这张决策树来排查。
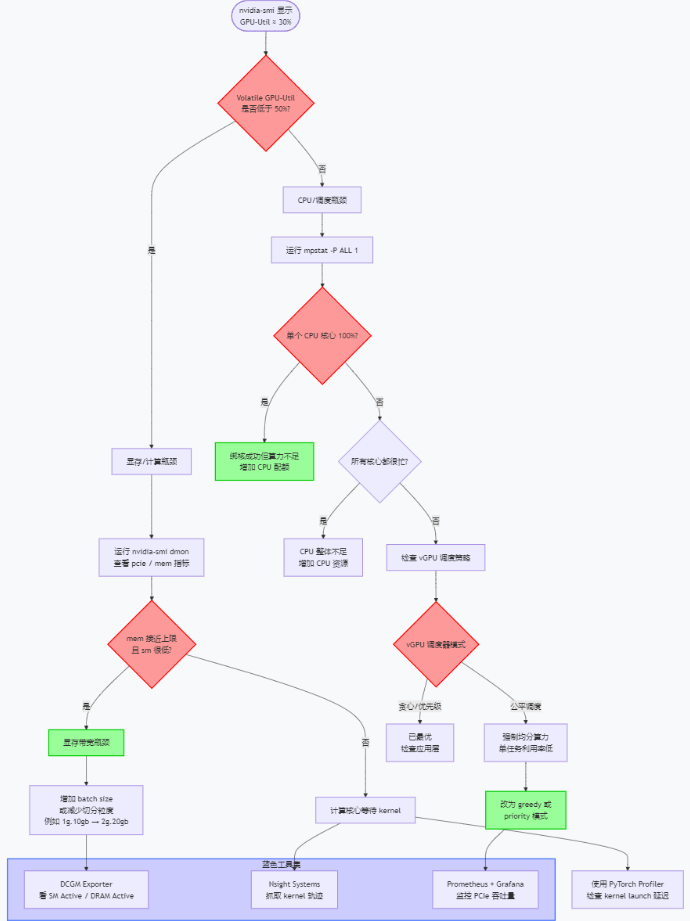
说明:
- 决策点:关键判断分支,帮助快速定位瓶颈类型。
- 操作点:针对性解决方案,如调整 batch size、增加 CPU 配额、修改 vGPU 调度模式。
- 工具集:2025年推荐的诊断工具,DCGM Exporter 监控 SM Active vs DRAM Active 可直接判断显存带宽是否瓶颈;Nsight Systems 提供 kernel 级分析。
五、终极配置清单
最后,直接上一份 2025 年实测有效的配置清单,照抄作业,至少能帮你从 30% 拉到 70% 以上。
5.1 K8s 集群层面
- Kubelet:–cpu-manager-policy=static –topology-manager-policy=single-numa-node
- 安装 Node Feature Discovery (NFD),自动识别
版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! MIG 设备。 - Device Plugin:使用 NVIDIA 官方 v0.15.0 以上版本,支持 MIG 与 vGPU 混布。
5.2 Pod 层面(关键!)
resources:
limits:
nvidia.com/gpu: 1 # 或 nvidia.com/mig-1g.10gb
cpu:"12" # 必须与绑核数量匹配
memory:"32Gi"
annotations:
# 2025 年通用注解,强制 NUMA 亲和
topology.cri.io/preferred:"single-numa-node"
# vGPU 专属:切分算力比例
vgpu.io/compute:"50"# 允许使用 50% 算力
vgpu.io/memory:"10240"# 10GB 显存
vgpu.io/scheduler:"greedy"# 贪心模式5.3 运行时调优
设置环境变量 NVIDIA_TF32_OVERRIDE=1(如果是 Ampere 及以上架构),启用 TF32,在不损失精度的前提下让 Tensor Core 跑满。
如果用的是 PyTorch 2.x+,务必设置 torch.set_float32_matmul_precision(‘high̵
六、总结
2025 年,GPU 早已不是单纯的硬件,而是云原生架构中的“一等公民”。面对 30% 的利用率,别再拍脑袋加卡了。
记住今天的三个核心点:选对切分方案、对齐 CPU 调度、用对排查工具。把 GPU 利用率从 30% 干到 80%,省下的可是几百万的真金白银。