一、系统框架
1. 方案一
1.1、框架图
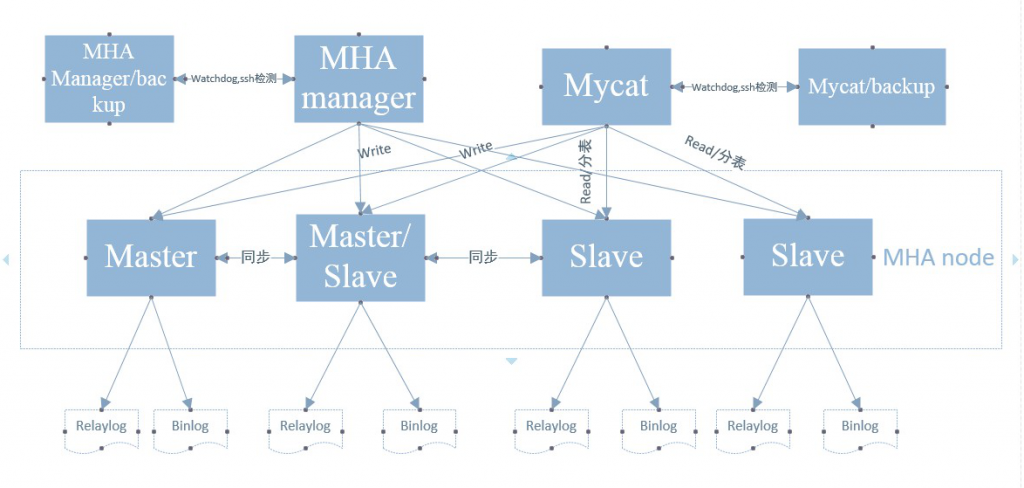
1.2框架说明:
1)Mycat实现mysql数据库的负载均衡、分库分表及读写分离;
2)MHA实现mysql数据库的主从库、快速故障切换;
3)mysql数据库最少为3台,一主两从,当master挂了之后,会把两台slave中选举出一台更新为master,实现数据库的高可用;
4)MHA,Mycat最少的数量为两台,其中一台服务器是激活状态,另外一台服务器是备份状态,备机通过Watchdog,ssh检测在使用的MHA manager,Mycat是否状态是不是正常,如果不正常,就进行服务器的清理工作,并在备份服务器启用新的MHA manager,Mycat,从而避免了MHA manager,Mycat的单点;
二、Mycat
1. Mycat配置说明
Mycat的配置文件都在conf目录里面,这里介绍几个常用的文件:
| 文件 | 说明 |
| server.xml | Mycat的配置文件,设置账号、参数等 |
| schema.xml | Mycat对应的物理数据库和数据库表的配置 |
| rule.xml | Mycat分片(分库分表)规则 |
Mycat的架构其实很好理解,Mycat是代理,Mycat后面就是物理数据库。和Web服务器的Nginx类似。对于使用者来说,访问的都是Mycat,不会接触到后端的数据库。
我们现在做一个主从、读写分离,简单分表的示例。结构如下图:
| 服务器 | IP |
| Mycat | 192.168.2.34 |
| database1 | 192.168.2.34 |
| database2 | 10.7.1.126 |
Mycat作为主数据库中间件,肯定是与代码弱关联的,所以代码是不用修改的,使用Mycat后,连接数据库是不变的,默认端口是8066。连接方式和普通数据库一样,如:jdbc:mysql://192.168.2.34:8066/
server.xml
<user name="test">
<property name="password">test</property>
<property name="schemas">lunch</property>
<property name="readOnly">false</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>重点关注下面这段,其他默认即可。
| 参数 | 说明 |
| user | 用户配置节点 |
| –name | 登录的用户名,也就是连接Mycat的用户名 |
| –password | 登录的密码,也就是连接Mycat的密码 |
| –schemas | 数据库名,这里会和schema.xml中的配置关联,多个用逗号分开,例如需要这个用户需要管理两个数据库db1,db2,则配置db1,dbs |
| –privileges | 配置用户针对表的增删改查的权限,具体见文档吧 |
我这里配置了一个账号test 密码也是test,针对数据库lunch,读写权限都有,没有针对表做任何特殊的权限。
schema.xml
schema.xml是最主要的配置项,首先看我的配置文件。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="lunch" checkSQLschema="false" sqlMaxLimit="100">
<table name="lunchmenu" dataNode="dn1" />
<table name="restaurant" dataNode="dn1" />
<table name="userlunch" dataNode="dn1" />
<table name="users" dataNode="dn1" />
<table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long" />
</schema>
<!-- 分片配置 -->
<dataNode name="dn1" dataHost="test1" database="lunch" />
<dataNode name="dn2" dataHost="test2" database="lunch" />
<!-- 物理数据库配置 -->
<dataHost name="test1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.2.34:3306" user="root" password="123456">
</writeHost>
</dataHost>
<dataHost name="test2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostS1" url="10.7.1.126:3306" user="root" password="123456">
</writeHost>
</dataHost>
</mycat:schema>| 参数 | 说明 |
| schema | 数据库设置,此数据库为逻辑数据库,name与server.xml中schema对应 |
| dataNode | 分片信息,也就是分库相关配置 |
| dataHost | 物理数据库,真正存储数据的数据库 |
每个节点的属性逐一说明:
schema:
| 属性 | 说明 |
| name | 逻辑数据库名,与server.xml中的schema对应 |
| checkSQLschema | 数据库前缀相关设置,建议看文档,这里暂时设为folse |
| sqlMaxLimit | select 时默认的limit,避免查询全表 |
table:
| 属性 | 说明 |
| name | 表名,物理数据库中表名 |
| dataNode | 表存储到哪些节点,多个节点用逗号分隔。节点为下文dataNode设置的name |
| primaryKey | 主键字段名,自动生成主键时需要设置 |
| autoIncrement | 是否自增 |
| rule | 分片规则名,具体规则下文rule详细介绍 |
dataNode
| 属性 | 说明 |
| name | 节点名,与table中dataNode对应 |
| datahost | 物理数据库名,与datahost中name对应 |
| database | 物理数据库中数据库名 |
dataHost
| 属性 | 说明 |
| name | 物理数据库名,与dataNode中dataHost对应 |
| balance | 均衡负载的方式 |
| writeType | 写入方式 |
| dbType | 数据库类型 |
| heartbeat | 心跳检测语句,注意语句结尾的分号要加。 |
2. Mycat应用场景
1) 数据库分表分库
配置如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="lunch" checkSQLschema="false" sqlMaxLimit="100">
<table name="lunchmenu" dataNode="dn1" />
<table name="restaurant" dataNode="dn1" />
<table name="userlunch" dataNode="dn1" />
<table name="users" dataNode="dn1" />
<table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long" />
</schema>
<!-- 分片配置 -->
<dataNode name="dn1" dataHost="test1" database="lunch" />
<dataNode name="dn2" dataHost="test2" database="lunch" />
<!-- 物理数据库配置 -->
<dataHost name="test1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.2.34:3306" user="root" password="123456">
</writeHost>
</dataHost>
<dataHost name="test2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostS1" url="10.7.1.126:3306" user="root" password="123456">
</writeHost>
</dataHost>
</mycat:schema>我在192.168.2.34、10.7.1.126均有数据库lunch。
lunchmenu、restaurant、userlunch、users这些表都只写入节点dn1,也就是192.168.0.2这个服务,而dictionary写入了dn1、dn2两个节点,也就是192.168.0.2、192.168.0.3这两台服务器。分片的规则为:mod-long。
主要关注rule属性,rule属性的内容来源于rule.xml这个文件,Mycat支持10种分表分库的规则,基本能满足你所需要的要求,这个必须赞一个,其他数据库中间件好像都没有这么多。
table中的rule属性对应的就是rule.xml文件中tableRule的name,具体有哪些分表和分库的实现,建议还是看下文档。我这里选择的mod-long就是将数据平均拆分。因为我后端是两台物理库,所以rule.xml中mod-long对应的function count为2,见下面部分代码:
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>2) 数据库读写分离
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="lunch" checkSQLschema="false" sqlMaxLimit="100">
<table name="lunchmenu" dataNode="dn1" />
<table name="restaurant" dataNode="dn1" />
<table name="userlunch" dataNode="dn1" />
<table name="users" dataNode="dn1" />
<table name="dictionary" primaryKey="id" autoIncrement="true" dataNode="dn1" />
</schema>
<!-- 分片配置 -->
<dataNode name="dn1" dataHost="test1" database="lunch" />
<!-- 物理数据库配置 -->
<dataHost name="test1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.2.34:3306" user="root" password="123456">
<readHost host="hostM1" url="10.7.1.126:3306" user="root" password="123456">
</readHost>
</writeHost>
</dataHost>
</mycat:schema>这样的配置与前一个示例配置改动如下:
删除了table分配的规则,以及datanode只有一个
datahost也只有一台,但是writehost总添加了readhost,balance改为1,表示读写分离。
以上配置达到的效果就是102.168.2.34为主库,10.7.1.126为从库。
注意:Mycat主从分离只是在读的时候做了处理,写入数据的时候,只会写入到writehost,需要通过mycat的主从复制将数据复制到readhost,这个问题当时候我纠结了好久,数据写入writehost后,readhost一直没有数据,以为是自己配置的问题,后面才发现Mycat就没有实现主从复制的功能,毕竟数据库本身自带的这个功能才是最高效稳定的。
至于其他的场景,如同时主从和分表分库也是支持的了,只要了解这个实现以后再去修改配置,都是可以
3) 注意事项
1 做分库分表和读写分离应用的必须是三台服务器
2 做分表的时候必须两张表的权限都为W写入权限
3. Mycat使用说明
Mycat的启动也很简单,启动命令在Bin目录:
##启动
mycat start
##停止
mycat stop
##重启
mycat restart如果在启动时发现异常,在logs目录中查看日志。
wrapper.log 为程序启动的日志,启动时的问题看这个
mycat.log 为脚本执行时的日志,SQL脚本执行报错后的具体错误内容,查看这个文件。mycat.log是最新的错误日志,历史日志会根据时间生成目录保存。
mycat启动后,执行命令不成功,可能实际上配置有错误,导致后面的命令没有很好的执行。
Mycat带来的最大好处就是使用是完全不用修改原有代码的,在mycat通过命令启动后,你只需要将数据库连接切换到Mycat的地址就可以了。如下面就可以进行连接了:
mysql -h192.168.2.34 -P8806 -uroot -p123456连接成功后可以执行sql脚本了。
所以,可以直接通过sql管理工具(如:navicat、datagrip)连接,执行脚本。我一直用datagrip来进行日常简单的管理,这个很方便。
Mycat还有一个管理的连接,端口号是9906.
mysql -h192.168.2.34 -P9906 -uroot -p123456连接后可以根据管理命令查看Mycat的运行情况,当然,喜欢UI管理方式的人,可以安装一个Mycat-Web来进行管理,有兴趣自行搜索。
简而言之,开发中使用Mycat和直接使用Mysql机会没有差别。
4. Mycat及框架性能验证
Mycat自身提供了一套基准性能测试工具,这套工具可以用于性能测试、疲劳测试等,包括分片表插入性能测试、分片表查询性能测试、更新性能测试、全局表插入性能测试等基准测试工具。 这里需要说明的一点是,分片表的性能测试不同于普通单表,因为它的数据是分布在几个Datahost上的,因此插入和查询,都必需要特定的工具,才能做到多个节点同时负载请求,通过观察每个主机的负载,能够确定是否你的测试是合理和正确的。
大量测试表明,当带宽不是问题而且带宽没有占满,比如千兆网网络连接的Mycat和MySQL服务器,以及测试客户端,(通常个人电脑到服务器的连接为100M),分片表的性能取决于后端部署MySQL的物理机的个数,比如每个MySQL的性能是5万Tps,则3台理论上是15万,而Mycat能达到80-95%之间,即12万以上。
关于带宽问题,是一个比较棘手的问题,通常需要监控交换机、MySQL服务器、Mycat服务器、以获取测试过程中的端口流量信息,才能确定是否带宽存在问题,另外,很多企业里,千兆交换机采用了百兆的普通网线的情况时有发生,防不胜防,所以,在不能控制的网络环境里,测试最大性能的目标通常无法实现。
另外,很多人测试的时候,并不知道MySQL直连的性能,因此无法正确比较Mycat的性能,所以,建议性能测试过程里,首先直连MySQL进行性能测试,可以同时直连多个MYSQL服务器,然后把测试结果累计,作为直连的性能指标,然后改为连接Mycat进行测试,这样的对比才是有价值的,当插件过大的时候,需要先排除是否存在MySQL冷热不均的现象,然后考虑Mycat性能调优。
5. MyCat 测试数据结构
表结构
DROP DATABASE IF EXISTS small;
USE small;
CREATE TABLE `tb_item` (
`id` bigint(20) NOT NULL COMMENT '商品id,同时也是商品编号',
`title` varchar(100) NOT NULL COMMENT '商品标题',
`sell_point` varchar(500) DEFAULT NULL COMMENT '商品卖点',
`price` bigint(20) NOT NULL COMMENT '商品价格,单位为:分',
`num` int(10) NOT NULL COMMENT '库存数量',
`barcode` varchar(30) DEFAULT NULL COMMENT '商品条形码',
`image` varchar(500) DEFAULT NULL COMMENT '商品图片',
`cid` bigint(10) NOT NULL COMMENT '所属类目,叶子类目',
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '商品状态,1-正常,2-下架,3-删除',
`created` datetime NOT NULL COMMENT '创建时间',
`updated` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `cid` (`cid`),
KEY `status` (`status`),
KEY `updated` (`updated`)
) COMMENT='商品表';6. MyCat 测试工具
1、测试工具介绍
测试工具在单独的包中(MyCat 社区提供),解压到任意机器中执行使用,跟MyCAT Server没有关联关系,此测试工具很强大,可以测试任意表,和任意数据库,测试工具下载: https://github.com/MyCATApache/Mycat-download,https://github.com/MyCATApache/Mycat-download/tree/master/1.6-RELEASE,其中的testtool.tar.gz
解压后,在bin目录里运行文中的测试脚本:
2、标准插入性能测试脚本
test_stand_insert_perf.bat:支持任意表的定制化业务数据的随机生成功能,在sql模板文件中用${int(1-100)}这种变量,测试程序会随机生成符合要求的值并插入数据库。
test_stand_insert_perf.bat jdbc:mysql://192.168.134.128:8066/small root 123456 100 “file=test-create.sql”
参数解释:
System.out.println(“input param,format: [jdbcurl] [user] [password] [threadpoolsize] [recordrange or customer sql file] “);
System.out.println(“jdbc:mysql://localhost:8066/TESTDB test test 10 \”0-300M,300M1-600M,600M1-900M\” “);
System.out.println(“jdbc:mysql://localhost:8066/TESTDB test test 10 file=mytempate.sql “);
jdbcurl:连接mycat的地址,格式为jdbc:mysql://localhost:8066/TESTDB
user:连接Mycat的用户名
password:密码
threadpoolsize:并发线程请求,可以在50-2000左右调整,看看哪种情况下的性能最好
recordrange:插入的分片系列以及对应的ID范围,minId-maxId然后逗号分开,对应多组分片的ID范围,如 0-200000,200001-400000,400001-600000,跟分片配置保持一致。也可以使用自定义sql
其中 test-create.sql 的内容如下:
total=2000000
sql=INSERT INTO TB_ITEM(ID,TITLE,SELL_POINT,PRICE,NUM,BARCODE,IMAGE,CID,STATUS,CREATED,UPDATED) VALUES (${int(0-9999)}${date(HHmmssSSS)}, '${char([A-Z,0-9]16:16)}', '${char([a-z,0-9]16:16)}', ${int(1111-9999)}, ${int(1111-9999)}, '${char([A-Z,0-9]16:16)}', '${char([a-f,0-9]16:16)}.jpg', ${int(0-9999)}, '${int(1-3)}', '${date(yyyyMMddHHmmss-[2000-2017]y)}', '${date(yyyyMMddHHmmss-[2000-2017]y)}');
目前支持的有以下类型变量:
Int:${int(..)}可以是${int(10-999)}或者${int(10,999)}前者表示从10到999的值,后者表示10或者999;
Date:日期如${date(yyyyMMddHHmmssSSS-[2014-2015]y)}表示从2014到2015年的时间,前面是输出
Char:字符串${char([0-9]2:2)}表示从0到9的字符,长度为2位(2:2),${char([a-f,0-9]8:8)}表示从a到f以及0到9的字符串随机组成,定常为8位;
Enmu:枚举,表示从指定范围内获取一个值,${enum(0000,0001,0002)}里面可以是任意字符串或数字等内容。
3、标准查询性能测试脚本
test_stand_select_perf.bat也支持sqlTemplate的变量方式,查询任意指定的sql 。
test_stand_select_perf.bat jdbc:mysql://192.168.134.128:8066/small root 123456 100 100 “file=test-select.sql”
其中test-select.sql的内容类似下面:
sql=select ID,TITLE,SELL_POINT,PRICE from TB_ITEM where id = ${int(0-99999)}${date(mmssSSS)};
表明查询id为${int(0-9999)}${date(HHmmssSSS)的随机SQL。
注意:Windows下file=xxx.slq需要加引号
7. 测试结果
1、分片表的录入性能测试
insert:250 线程,300万数据(tps)
| 环境\数据量 | 50万 | 100万 | 150万 | 200万 | 250万 | 300万 |
| Mycat | ||||||
| mysql | ||||||
| HA |
2、分片表的查询性能测试
select:250 线程,300万数据(qps)
| 环境\数据量 | 50万 | 100万 | 150万 | 200万 | 250万 | 300万 |
| Mycat | ||||||
| mysql | ||||||
| HA |
8. 测试注意事项
测试过程: 每次测试,建议先执行重建表的操作,以保证测试环境的一致性;
首先参考MyCAT性能调优,确保整个系统达到最优配置;
性能测试,建议先小规模压力预热10-20分钟,这是众所周知的Java的特性,越跑越快;
带宽应该是至少100M,建议千兆;
压力程序在另一台,压力程序的机器也可以由性能差的机器来代替;
有条件的话,分片库在不同的MYSQL实例上,如20个分片,每个MYSQL实例7个分片,而且最好有多台MYSQL物理机。
9. MyCat 并发
并发线程数表明同时至少有多少个Mysql连接会被打开,当SQL不跨分片的时候,并发线程数=MYSQL连接数。在Mycat conf/schema.xml中,将minCon设置为>=并发连接数,这种情况下重启MYCAT,会初始建立minCon个连接,并发测试结果更好。另外,也可以验证是否当前内存设置,以及MYSQL是否支持开启这么多连接,若无法支持,则logs/mycat.log日志中会有告警错误信息,建议测试过程中tail –f logs/mycat.log 观察有无错误信息。
另外,开启单独的Mycat管理窗口,mysql –utest –ptest –P9066 然后运行 show @@datasource 可以看到后端连接的使用情况。Show @@threadpool 可以看线程和SQL任务积压的情况。 也可以同时启动多个测试程序,在不同的机器上,并发进行测试,每个测试程序写入一个分片的数据范围,对于1个亿的数据插入测试来说,可能效果更好,毕竟单机并发线程50个左右已经差不多极限。
具体的性能优化见(五、性能优化)章节;
10. 性能优化
首先,要保证HA框架中,JVM,操作系统,mysql,mycat已经是最优的配置
1、JVM调优
内存占用分两部分:java堆内存+直接内存映射(DirectBuffer占用),建议堆内存适度大小,直接映射内存尽可能大,两种一起占据操作系统的1/2-2/3的内存。
下面以服务器16G内存为例,Mycat堆内存4G,直接内存映射6G,JVM参数如下:
-server -Xms4G –Xmx4G XX:MaxPermSize=64M -XX:MaxDirectMemorySize=6G
用mycat console等命令启动MyCAT的,JVM参数都在conf\wrapper.con文件中,下面是一段实例:
# Java Additional Parameters
wrapper.java.additional.5=-XX:MaxDirectMemorySize=2G
wrapper.java.additional.6=-Dcom.sun.management.jmxremote
# Initial Java Heap Size (in MB)
wrapper.java.initmemory=2048
# Maximum Java Heap Size (in MB)
wrapper.java.maxmemory=20482、操作系统调优
最大文件句柄数量的修改,设置为5000-1万,在Mycat Server和Mysql数据库的机器上都设置。Linux操作系统对一个进程打开的文件句柄数量的限制(也包含打开的SOCKET数量,可影响MySQL的并发连接数目).这个值可用ulimit命令来修改,但ulimit命令修改的数值只对当前登录用户的目前使用环境有效,系统重启或者用户退出后就会失效。
3、Mysql调优
最大连接数设置为2000
[mysqld]中有参数
max_connections = 2000
mysql> show global status like 'Max_used_connections';MySQL服务器过去的最大连接数是245,没有达到服务器连接数上限256,应该没有出现1040错误,比较理想的设置是:
Max_used_connections / max_connections * 100% ≈ 85%
最大连接数占上限连接数的85%左右,如果发现比例在10%以下,MySQL服务器连接上线就设置得过高了。
4、Mycat调优
1)Conf/log4j.xml中,日志级别调整为至少info级别,默认是debug级别,用于排查错误,不能用于性能测试和正式生产中。
conf/server.xml中 有如下参数可以调整:
2) processors,cpu的核心数
<system>
<!— CPU核心数越多,可以越大,当发现系统CPU压力很小的情况下,可以适当调大此参数,如4核心的4CPU,可以设置为16,24核心的可以最大设置为128——>
<property name="processors">1</property>3)processorExecutor,processor的线程池大小;
为每个processor的线程池大小,建议可以是16-64,根据系统能力来测试和确定。
<property name="processorExecutor">16</property>
</system>System中以下重要参数也根据情况进行调整
3)processorBufferPool :
每个processor分配的Socket Direct Buffer,用于网络通信,每个processor上管理的所有连接共享;
processorBufferPool参数的调整,需要观察show @@processor的结果来确定:
BU_PERCENT为已使用的百分比、BU_WARNS为Socket Buffer Pool不够时,临时创新的新的BUFFER的次数,若百分比经常超过90%并且BU_WARNS>0,则表明BUFFER不够,需要增大processorBufferPool。基本上,连接数越多,并发越高,需要的POOL越大,建议BU_PERCENT最大在40-80%之间。
4)processorBufferChunk为Pool的最小分配单元,每个POOL的容量即为processorBufferPool/processorBufferChunk,默认前者为1024 * 1024 * 16=16M,后者为4096字节。
conf/schema.xml中有如下参数可以调整:
5) checkSQLschema
,checkSQLschema属性建议设置为false,要求开发中,不能在sql中添加数据库的名称,如select * from TESTDB.company,这样可以优化SQL解析。
6) 最大连接池maxCon
<dataHost name="localhost1" maxCon="500" minCon="10" balance="0"
dbType="mysql" dbDriver="native" banlance="0">
<!—最大连接池maxCon,可以改为1000至2000,同一个Mysql实例上的所有datanode节点的共享本dataHost 上的所有物理连接>性能测试的时候,建议minCon=maxCon= mysql max_connections
设为2000左右。
另外,读写分离是否开启,根据环境的配置来决定。
7)缓存优化调整:
Show @@cache命令展示了缓存的使用情况,经常观察其结果,需要时候进行调整:

一般来说:若CUR接近MAX,而PUT大于MAX很多,则表明MAX需要增大,HIT/ACCESS为缓存命中率,这个值越高越好。重新调整缓存的最大值以后,观测指标都会跟随变化,调整是否有效,主要观察缓存命中率是否在提升,PUT则下降。
目前缓存服务的配置文件为:cacheservice.properties,主要使用的缓存为enhache,enhache.xml里面设定了enhance缓存的全局属性,下面定义了几个缓存:
#used for mycat cache service conf
factory.encache=org.opencloudb.cache.impl.EnchachePooFactory
#key is pool name ,value is type,max size, expire seconds
pool.SQLRouteCache=encache,10000,1800
pool.ER_SQL2PARENTID=encache,1000,1800
layedpool.TableID2DataNodeCache=encache,10000,18000
layedpool.TableID2DataNodeCache.TESTDB_ORDERS=50000,180008)SQLRouteCache为SQL 解析和路由选择的缓存,这个大小基本相对固定,就是所有SELECT语句的数量。
processors数值的影响范围。
buffer和buffer队列大小。
processors数值定义了如下几个类的实例个数:
NIOProcessor
NIOReactorPool
AsynchronousChannelGroup
NIOProcessor类,持有所有的前后端连接,定期的空闲检查和写队列检查。要完成这个动作。Mycat是通过遍历NIOProcessor持有的所有连接来完成的。
所以,可以适当的根据系统性能调整NIOProcessor的个数。使得前、后段连接可以均匀的分布在每个NIOProcessor上。这样,就可以加快每次的空闲检查和写队列检查。快速的将空闲的连接关闭,减轻服务器的内存使用量。
NIOReactor是NIO中具体执行selector的类,当满足感兴趣的事件发生的时候,他就通知上次逻辑进行具体的处理。所以,NIOReactor的个数等于具体事件处理器的个数。如果系统的配置允许的话,应该尽可能的增大NIOReactor的数量。默认值是系统核心数。
AsynchronousChannelGroup是AIO中必须提供的一个组成部分。AsynchronousChannelGroup根据processors的数值,确定实例数和channelGroup组内的线程池大小。后端AIO连接循环取AsynchronousChannelGroup数组中的实例。所以。如果是在AIO模式下使用Mycat的话,调整这个参数也是有必要的。默认值是系统
7) processorBufferPool
因为,所有的NIOProcessor共享一个buffer pool。
BufferPool的总长度 = bufferPool / bufferChunk
我们可以连接到Mycat管理端口上,使用show @@processor命令列出所有的processor状态。
查看列: FREE_BUFFER、TOTAL_BUFFER、BU_PERCENT。
如果FREE_BUFFER的数值过小,则说明配置的buffer pool大小可能不够。这时候就要手动配置根据公式这个属性了,pool的大小最好是bufferChunk的整数倍。例如,配置buffer pool的大小为:5000 server.xml文件中定义
<property name="processorBufferPool">20480000</property>buffer pool是线程内buffer pool,这个值可以根据processors的数值计算出来
9)Mycat大数据量查询调优:
1.返回结果比较多
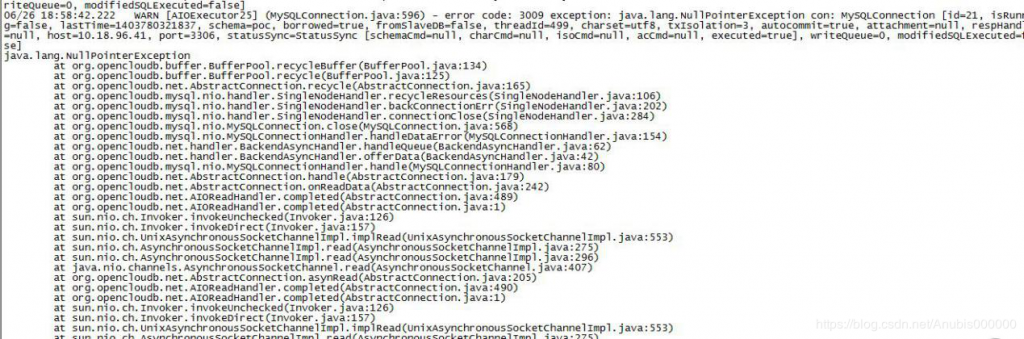
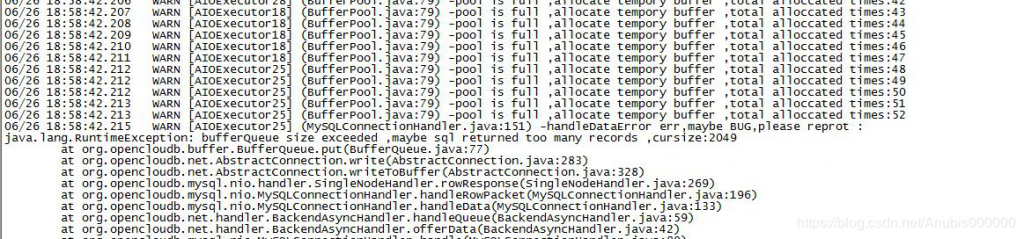
建议调整frontWriteQueueSize 在系统许可的情况下加大,默认值*3
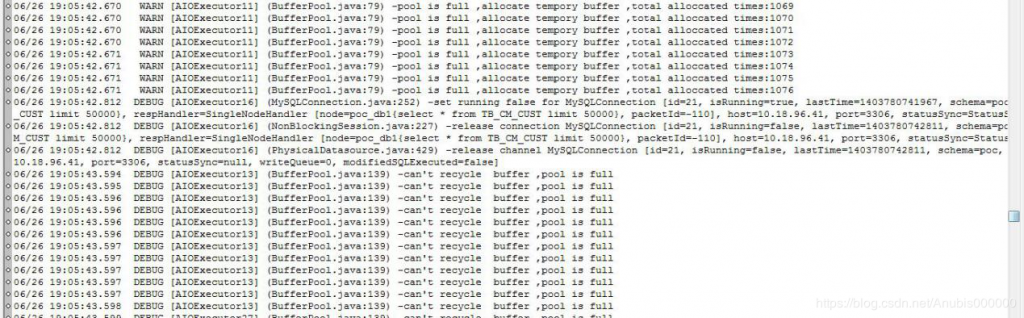
这个原因是因为返回数据太多
这里做了一个改进,就是超过POOL以后,仍然创建临时的BUFFER供使用,但这些不回收。
这样的情况下,需要增加BUFFER参数
调整 processorBufferPool = 默认值*2, 不够的情况下,继续加大