一、ActiveMQ集群原理
ActiveMQ集群原理,使用ZooKeeper集群注册所有的ActiveMQ Broker。只有其中的一个Broker可以对外提供服务,被视为master。而其他的Broker处于待机状态,被视为slave。而此时slave只是做数据的主从同步。
如果master因故障而不能提供服务,ZooKeeper集群会从slave中选举出一个Broker充当 master。slave连接 master并同步它们的存储状态,slave不接受客户端连接。所有的存储操作都将被复制到连接至master的slave上。
如果master宕机了,得到了最新更新的slave会成为master。而故障节点在恢复后会重新加入到集群中并连接 master进入slave模式。
需要同步的消息操作都将等待存储状态被复制到其他节点的操作完成后才能完成。
所以,如果你配置了replicas=3,那么法定大小是(3/2)+1=2。master将会存储并更新然后等待(2-1)=1个slave存储和更新完成,才汇报success。
1.1 Master-Slave集群
由至少3个节点组成,一个Master节点,其他为Slave节点。只有Master节点对外提供服务,Slave节点处于等待状态。当主节点宕机后,从节点会推举出一个节点出来成为新的Master节点,继续提供服务。
优点是可以解决多服务热备的高可用问题,缺点是无法解决负载均衡和分布式的问题。
1.2 Broker Cluster集群
Broker-Cluster部署方式中,各个broker通过网络互相连接,并共享queue。当broker-A上面指定的queue-A中接收到一个message处于pending状态,而此时没有consumer连接broker-A时。如果cluster中的broker-B上面有一个consumer在消费queue-A的消息,那么broker-B会先通过内部网络获取到broker-A上面的message,并通知自己的consumer来消费。
优点是可以解决负载均衡和分布式的问题。但不支持高可用。
我们知道
- master/slave模式下,消息会被逐个复制
- cluster模式下,请求会被自动派发
鱼与熊掌兼得法是最完美的解决方案就是将两者结合起来。
二、部署准备工作
- 这里使用ZK搭建MASTER SLAVE
- 这里使用BROKER CLUSTER把两个“组”合并在一起
Master Slave + Broker Cluster 模式结构图
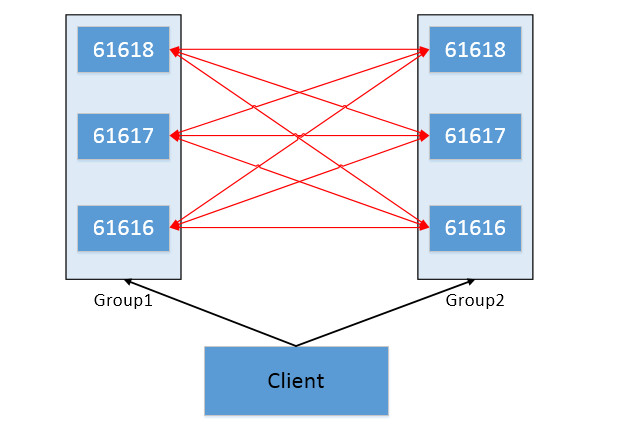
服务器规划
| Hostname | IP | Install APP |
| zk_group1_2_node | 192.168.0.240 | ZooKeeper |
| zk_group1_2_node | 192.168.0.250 | ZooKeeper |
| zk_group1_2_node | 192.168.0.225 | ZooKeeper |
| mq_ group1_node1_2_3 | 192.168.0.231 | ActiveMQ |
| mq_group2_node4_5_6 | 192.168.0.241 | ActiveMQ |
集群规划
| name | openwire | amqp | stomp | mptt | ws | admin | zk | group |
| mq1 | 61616 | 5672 | 61613 | 1883 | 61614 | 8161 | 2181 | group1 |
| mq2 | 61617 | 5673 | 61623 | 1884 | 61714 | 8162 | 2181 | group1 |
| mq3 | 61618 | 5674 | 61633 | 1885 | 61814 | 8163 | 2181 | group1 |
| mq4 | 61616 | 5672 | 61613 | 1883 | 61614 | 8161 | 2182 | group2 |
| mq5 | 61617 | 5673 | 61623 | 1884 | 61714 | 8162 | 2182 | group2 |
| mq6 | 61618 | 5674 | 61633 | 1885 | 61814 | 8163 | 2182 | group2 |
| zk1 | – | ̵ | – | – | – | – | 2181 | group1 |
| zk2 | – | – | – | – | – | – | 2182 | group2 |
2.1 ZooK版权声明:本文遵循 CC 4.0 BY-SA 版权协议,若要转载请务必附上原文出处链接及本声明,谢谢合作! eeper集群部署
group1组三个节点,不一一罗列,这里以一个节点安装配置说明:
#创建数据与日志文件目录
mkdir -p /data/zookeeper/{data,logs}
#下载与解压
wget -P /usr/local/ https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz && tar -zxf zookeeper-3.4.13.tar.gz && mv zookeeper-3.4.14 zookeeper-cluster
#创建用户与目录授权
useradd -s /sbin/nologin -M -U zookeeper && chown -R zookeeper:zookeeper /usr/local/zookeeper-cluster /data/zookeeper/
#配置环境变量
# zookeeper
export ZK_LOGS=/data/zookeeper/logs/
export ZK_HOME=/usr/local/zookeeper-cluster
export PATH=$ZK_HOME/bin:$PATH日志输出标准化设置
#修改zookeeper.out输出路劲
将ZOO_LOG_DIR="."
修改为:ZOO_LOG_DIR="$ZK_LOGS"
#修改日志按照每天滚动输出(../bin/zkEnv.sh ../conf/log4j.properties)
将ZOO_LOG4J_PROP="INFO,CONSOLE"
修改为:ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
将log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
修改为:log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender
其它可配置参数:
log4j.appender.ROLLINGFILE.File=zookeeper.log
log4j.appender.ROLLINGFILE.DataPattern='.'yyyy-MM-dd-HH-mm
log4j.appender.ROLLINGFILE.Threshold=debug
log4j.appender.ROLLINGFILE.encoding=UTF-8
log4j.appender.ROLLINGFILE.Append=false
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLINGFILE.layout.ConversionPattern= [%d{yyyy-MM-dd HH\:mm\:ss}]%-5p %c(line\:%L) %x-%m%nzookeeper 配置
所有节点配置文件如下
#新增配置文件
more /usr/local/zookeeper-cluster/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/data/logs
snapCount=2
clientPort=2181
autopurge.snapRetainCount=50
autopurge.purgeInterval=1
server.0 = 192.168.0.240:2888:3888
server.1 = 192.168.0.250:2888:3888
server.2 = 192.168.0.225:2888:3888创建标识文件
#对应节点主机创建标识文件,标识文件内容对应zoo.cfg中server.x;x标识节点标识号,具有唯一性。
如:
192.168.0.240节点创建
echo "0" >/data/zookeeper/data/myid
192.168.0.250节点创建
echo "1" >/data/zookeeper/data/myid
192.168.0.225节点创建
echo "2" >/data/zookeeper/data/myid配置启动文件
more /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:zookeeper
#processname:zookeeper
export JAVA_HOME=/usr/java/jdk1.8.0_172
case $1 in
start) su - zookeeper -s /bin/bash -c '/usr/local/zookeeper-cluster/bin/zkServer.sh start';;
stop) su - zookeeper -s /bin/bash -c '/usr/local/zookeeper-cluster/bin/zkServer.sh stop';;
status) su - zookeeper -s /bin/bash -c '/usr/local/zookeeper-cluster/bin/zkServer.sh status';;
restart) su - zookeeper -s /bin/bash -c '/usr/local/zookeeper-cluster/bin/zkServer.sh restart';;
*) echo "require start|stop|status|restart" ;;
esac - 启动
[root@zk_group1_2_node data]# service zookeeper status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-cluster/bin/../conf/zoo.cfg
Mode: leader
[root@zk_group1_2_node data]# service zookeeper status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-cluster/bin/../conf/zoo.cfg
Mode: follower
[root@zk_group1_2_node data]# service zookeeper status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-cluster/bin/../conf/zoo.cfg
Mode: follower2.2 ActiveMQ集群部署
由于这涉及到两个组6个ActiveMQ的实例配置,如果把6个配置全写出来是完全没有必要的,因此我就把配置分成两组来写吧。每个组的配置对于其组内各个节点都为一致的,除去那些个端口号。Group1的配置(保持6个实例中brokerName全部为一致
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="activemq-cluster" dataDirectory="${activemq.data}" useJmx="true" >MASTER SLAVE+BROKER CLUSTER的搭建-Group1的配置
broker cluster的配置是用来确保每一台都可以和Group2中的各个节点保持同步
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="activemq-cluster" dataDirectory="${activemq.data}" useJmx="true" >
<networkConnectors>
<networkConnector name="group1-broker1" uri="static(tcp://192.168.0.241:61616,tcp://192.168.0.241:61617,tcp://192.168.0.241:61618)" duplex="true" />
</networkConnectors>
<destinationPolicy>一般在部署ActiveMQ集群的时候,更倾向于使用基于ZooKeeper的Replicated LevelDB Store方式,该方式是Master Slave部署方案的其中一种策略,也是在多台主机实现ActiveMQ集群的主流部署方式。具体配置如下
<persistenceAdapter>
<!--
<kahaDB directory="${activemq.data}/kahadb"/>
-->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62621"
zkSessionTimeout="3s"
zkAddress="192.168.0.240:2181,192.168.0.250:2181,192.168.0.225:2181"
zkPath="/activemq-cluster/leveldb-stores/group1"
hostname="192.168.0.231"
sync="local_disk"
/>
</persistenceAdapter>MASTER SLAVE+BROKER CLUSTER的搭建-Group2的配置
broker cluster的配置是用来确保每一台都可以和Group1中的各个节点保持同步
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="activemq-cluster" dataDirectory="${activemq.data}" useJmx="true" >
<networkConnectors>
<networkConnector name="group2-broker1" uri="static(tcp://192.168.0.231:61616,tcp://192.168.0.231:61617,tcp://192.168.0.231:61618)" duplex="true" />
</networkConnectors>
<destinationPolicy>- 其他配置属性
下表列举了在networkConnector标签中还可以使用的属性以及其意义。请特别注意其中的duplex属性。如果只从字面意义理解该属性,则被称为“双工模式”;如果该属性为true,当这个节点使用Network Bridge连接到其它目标节点后,将强制目标也建立Network Bridge进行反向连接。其目的在于让消息既能发送到目标节点,又可以通过目标节点接受消息,但实际上大多数情况下是没有必要的,因为目标节点一般都会自行建立连接到本节点。所以,该duplex属性的默认值为false。
属性名称 默认值 属性意义
name bridge 名称
dynamicOnly false 如果为true, 持久订阅被激活时才创建对应的网路持久订阅。
decreaseNetworkConsumerPriority false 如果为true,网络的消费者优先级降低为-5。如果为false,则默认跟本地消费者一样为0.
excludedDestinations empty 不通过网络转发的destination
dynamicallyIncludedDestinations empty 通过网络转发的destinations,注意空列表代表所有的都转发。
staticallyIncludedDestinations empty 匹配的都将通过网络转发-即使没有对应的消费者,如果为默认的“empty”,那么说明所有都要被转发
duplex false 已经进行详细介绍的“双工”属性。
prefetchSize 1000 设置网络消费者的prefetch size参数。如果设置成0,那么就像之前文章介绍过的那样:消费者会自己轮询消息。显然这是不被允许的。
suppressDuplicateQueueSubscriptions false 如果为true, 重复的订阅关系一产生即被阻止(V5.3+ 的版本中可以使用)。
bridgeTempDestinations true 是否广播advisory messages来创建临时destination。
alwaysSyncSend false 如果为true,非持久化消息也将使用request/reply方式代替oneway方式发送到远程broker(V5.6+ 的版本中可以使用)。
staticBridge false 如果为true,只有staticallyIncludedDestinations中配置的destination可以被处理(V5.6+ 的版本中可以使用)。
以下这些属性,只能在静态Network Connectors模式下使用
| 属性名称 | 默认值 | 属性意义 |
|---|---|---|
| initialReconnectDelay | 1000 | 重连之前等待的时间(ms) (如果useExponentialBackO |
| useExponentialBackOff | true | 如果该属性为true,那么在每次重连失败到下次重连之前,都会增大等待时间 |
| maxReconnectDelay | 30000 | 重连之前等待的最大时间(ms) |
| backOffMultiplier | 2 | 增大等待时间的系数 |
一般在部署ActiveMQ集群的时候,更倾向于使用基于ZooKeeper的Replicated LevelDB Store方式,该方式是Master Slave部署方案的其中一种策略,也是在多台主机实现ActiveMQ集群的主流部署方式。具体配置如下
<persistenceAdapter>
<!--
<kahaDB directory="${activemq.data}/kahadb"/>
-->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62621"
zkSessionTimeout="3s"
zkAddress="192.168.0.240:2182,192.168.0.250:2182,192.168.0.225:2182"
zkPath="/activemq-cluster/leveldb-stores/group2"
hostname="192.168.0.241"
sync="local_disk"
/>
</persistenceAdapter>如上配置属性:
directory:表示ActiveMQ集群消息持久化保存到服务器上的路径,注意该路径一定要先创建好。
replicas:表示ActiveMQ集群的节点个数。
bind:表示当这个节点成为master后,绑定的机器的地址与端口。此处默认0.0.0.0:0表示绑定到本机所有可用IP,而端口是随机的。
zkAddress:表示ZooKeeper的ip和port。如果是ZooKeeper集群的话,则用逗号隔开。
zkSessionTimeout:表示ActiveMQ与ZooKeeper集群连接的会话超时时间。
hostname:表示本机的IP地址。服务器根据不同的IP地址做出改变,其他配置相同。
sync:在消息被消费完成前,同步信息所存贮的策略。如果有多种策略用逗号隔开,ActiveMQ会选择较强的策略。而如果有local_mem, local_disk这两种策略的话,那么ActiveMQ则优先选择local_disk策略,存储在本地硬盘。
zkPath:表示ActiveMQ在ZooKeeper集群上创建的znode节点的路径,也即是ZooKeeper选举信息交换的存贮路径。三、Master-Slave + Broker Cluster 集群验证
3.1 ActiveMQ 日志查看

3.2 ZooKeeper 注册信息
如: ZooKeeper 各自的组节点中可查看到 ActiveMQ各自组的注册情况
ActiveMQ 的group1组在 ZooKeeper group1中的注册信息如下:
[zk: localhost:2181(CONNECTED) 0] ls /activemq-cluster/leveldb-stores
group1
[zk: localhost:2181(CONNECTED) 0] ls /activemq-cluster/leveldb-stores/group1
[00000000002, 00000000000, 00000000001]
[zk: localhost:2181(CONNECTED) 2] get /activemq-cluster/leveldb-stores/group1/00000000000
{"id":"activemq-cluster","container":null,"address":"tcp://192.168.0.231:62621","position":-1,"weight":1,"elected":"0000000000"}
cZxid = 0x400000133
ctime = Fri Apr 19 17:00:37 CST 2019
mZxid = 0x40000013b
mtime = Fri Apr 19 17:01:09 CST 2019
pZxid = 0x400000133
cversion = 0
dataVersion = 4
aclVersion = 0
ephemeralOwner = 0x20000b4dc040013
dataLength = 128
numChildren = 0
[zk: localhost:2181(CONNECTED) 3]ActiveMQ 的group2组在 ZooKeeper group2中的注册信息如下:
[zk: localhost:2182(CONNECTED) 0] ls /activemq-cluster/leveldb-stores
group2
[zk: localhost:2182(CONNECTED) 0] ls /activemq-cluster/leveldb-stores/group2
[00000000003, 00000000004, 00000000005]
[zk: localhost:2182(CONNECTED) 2] get /activemq-cluster/leveldb-stores/group2/00000000003
{"id":"activemq-cluster","container":null,"address":"tcp://192.168.0.241:62621","position":-1,"weight":1,"elected":"0000000003"}
cZxid = 0x400000123
ctime = Fri Apr 19 17:00:37 CST 2019
mZxid = 0x40000011b
mtime = Fri Apr 19 17:01:09 CST 2019
pZxid = 0x400000134
cversion = 0
dataVersion = 4
aclVersion = 0
ephemeralOwner = 0x20000b4dc240018
ataLength = 128
numChildren = 0
[zk: localhost:2182(CONNECTED) 3]3.3 ActiveMQ 管理平台
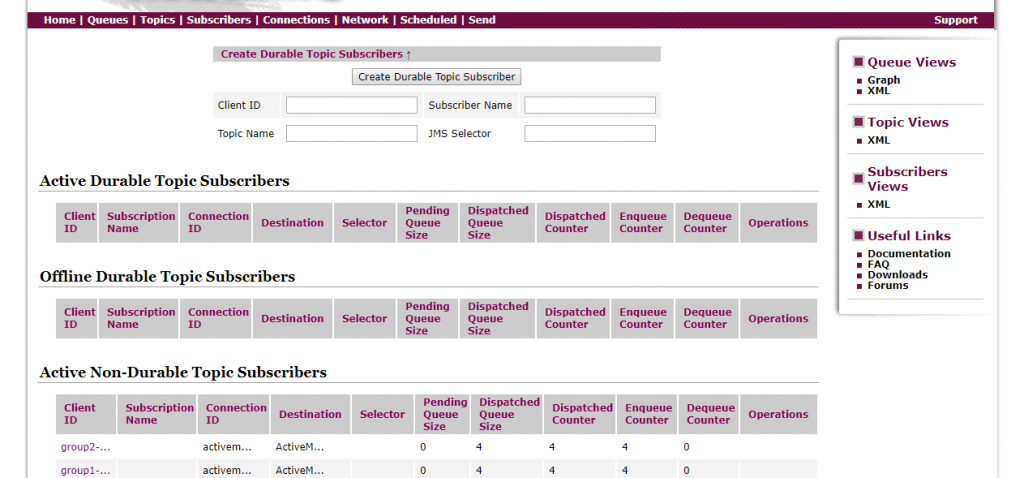
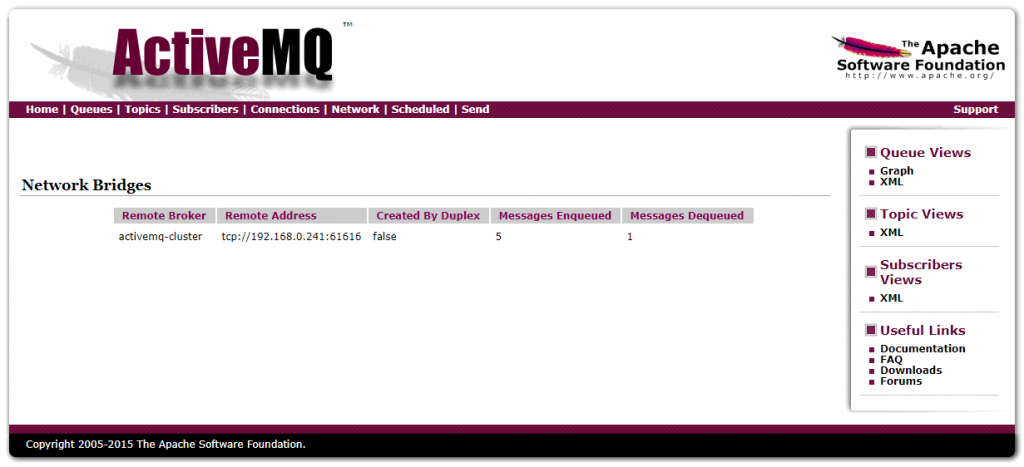
3.4 python 操作验证
附py:连接不同组节点,操作推送与接收动作,观察管理平台(队列/主题)消费前后变化
import stomp
import time
queue_name = '/queue/SampleQueue'
topic_name = '/topic/SampleTopic'
listener_name = 'SampleListener'
class SampleListener(object):
def on_message(self, headers, message):
print('headers: %s' % headers)
print('message: %s' % message)
# 推送到队列queue
def send_to_queue(msg):
conn = stomp.Connection10([('192.168.0.231', 61613)])
conn.start()
conn.connect()
conn.send(queue_name, msg)
conn.disconnect()
# 推送到主题
def send_to_topic(msg):
conn = stomp.Connection10([('192.168.0.231', 61613)])
conn.start()
conn.connect()
conn.send(topic_name, msg)
conn.disconnect()
##从队列接收消息
def receive_from_queue():
conn = stomp.Connection10([('192.168.0.241', 61613)])
conn.set_listener(listener_name, SampleListener())
conn.start()
conn.connect()
conn.subscribe(queue_name)
time.sleep(1) # secs
conn.disconnect()
##从主题接收消息
def receive_from_topic():
conn = stomp.Connection10([('192.168.0.241', 61613)])
conn.set_listener(listener_name, SampleListener())
conn.start()
conn.connect()
conn.subscribe(topic_name)
while 1:
send_to_topic('topic')
time.sleep(3) # secs
conn.disconnect()
if __name__ == '__main__':
send_to_queue('len 123')
receive_from_queue()
# send_to_topic('len 345')
# receive_from_topic()3.5 注意事项
- 关于防火墙:请记得关闭您Linux服务器上对需要公布的IP和端口的限制;
- 关于hosts路由信息:由于基于组播的动态发现机制,能够找到的是目标ActiveMQ服务节点的机器名,而不是直接找到的IP。所以请设置当前服务节点的hosts文件,以便当前ActiveMQ节点能够通过hosts文件中的IP路由关系,得到机器名与IP的映射;
- 关于哪些协议能够被用于进行Network Bridges连接:根据笔者以往的使用经验,只有tcp头的uri格式(openwire协议)能够被用于Network Bridges连接;当然您可以使用auto头,因为其兼容openwire协议;另外,您还可以指定为附加nio头;
四、结束语
从生产环境的高可用性来説,如果需要使用完美解决方案的话我们至少需要以下这些实体机。
2台实体机
- 每台虚出3个子节点来(用VM),供3个MQ实例运行使用,2*3共为6个
- 并且一台实体机必须承载一个GROUP,同一个GROUP最好不要跨实体机或虚拟
2台实体机
- 每台虚出3个子节点来(用VM),供3个ZK 节点使用,2*3共为6个
- 并且一台实体机必须承载一个ZK GROUP,同一个ZK GROUP最好不要跨实体机或虚拟
同一台实体机上不得又安装ZK又安装MQ
上述是ActiveMQ Master Slave + Broker Cluster的最小化配置,为了得到更高的高可用性,建议6个MQ实例间全部需要有物理机承载。
但是,上述情况是用于应对百万级并发消息的生产环境而言才需要如此大动干戈,对于常规环境笔者建议:
搞两台高配置的VM分散在两台不同的实体机,做MASTER SLAVE即可,当然笔者强烈建议使用ZK做ActiveMQ的Master Slave,ZK可
参考文献
https://www.cnblogs.com/arjenlee/p/9303229.html
http://www.ppzedu.com/archives/602.html