图文记录下shell多进程
虽说shell的多进程是后台执行,但是学会了再写一些脚本的时候非常方便
先看传统的后台多进程方式,写个shell来举例
先是正常的运行
[root@guan ~]# cat>test.sh<<'eof'
> #!/bin/bash
> start=`date +%s`
> for i in `seq 10`;do
> echo $i;sleep 2
> done
> echo 'Time:' "$((`date +%s`-start))"
> eof
[root@guan ~]# sh test.sh
1
2
3
4
5
6
7
8
9
10
Time: 20
[root@guan ~]#然后是后台运行来节约时间
[root@guan ~]# cat>test.sh<<'EOF'
> #!/bin/bash
> start=`date +%s`
> for i in `seq 10`;do
> { echo $i;sleep 2; }& #后台运行
> done
> wait #等待所有后台进程运行完成
> echo 'Time:' "$((`date +%s`-start))"
> EOF
[root@guan ~]# sh test.sh
1
2
5
6
7
9
4
8
3
10
Time: 2
[root@guan ~]#从上面结果对比发现时间大大缩短,但是缺点是不能控制数量
然后因为wait特性我们可以用它来配合数字来自定并发的数量
[root@guan ~]# cat>test.sh<<'EOF'
#!/bin/bash
max_process=5;
start=`date +%s`
for i in `seq 10`;do
{ echo $i;sleep 2; }& #后台运行
((count++));((do_count++)) # 次数和运行的次数计数
[ "$do_count" -eq '10' ] && { wait;break; } # 这里的10是需要执行的总次数,运行过的次数等于总次数就等待所有后台退出,但是假设每次并发的次数是3,最后有一个进程,上下俩行就是为了防止这种情况出现
[ "$count" -eq "$max_process" ] && { wait;count=0; }
done
echo 'Time:' "$((`date +%s`-start))"
EOF
[root@guan ~]# sh test.sh
1
2
4
5
3
6
7
10
9
8
Time: 4
[root@guan ~]#这种还要考虑需要并发的进程数量在总次数下是否有余数的可能,后面我发现了可以用mkfifo来实现并发,代码更
无名管道: 就是我们经常使用的 netstat -antp | grep "abc"
那个|就是管道,只不过是无名的,可以直接作为两个进程的数据通道
有名管道:mkfilo 可以创建一个管道文件 ,例如mkfifo fifo_file
管道有一个特点,如果管道中没有数据,那么取管道数据的操作就会停滞,直到
管道内进入数据,然后读出后才会终止这一操作,同理,写入管道的操作
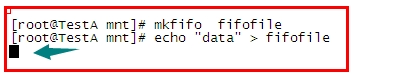

如果没有读取操作,这一个动作也会停滞。
当我们试图用echo想管道文件中写入数据时,由于没有任何进程在对它做读取操作,所以
它会一直停留在那里等待读取操作,此时我们在另一终端上用cat指令做读取操作
你会发现读取操作一旦执行,写入操作就可以顺利完成了,同理,先做读取操作也是一样的(不信可以自行测试)
后面发现的多进程就是利用管道的读写来控制,exec
exec绑定文件操作符后我们来试试按行读取会有啥现象
[root@guan ~]# exec 5<>test_fifo
[root@guan ~]# echo '123' >&5
[root@guan ~]# read -u5 #-u选项是表示从文件描叙符里读取管道里的一行
[root@guan ~]# read -u5
^C #上面管道里只有一行,读取第二行会停滞在这
[root@guan ~]# echo -e '123\n123' >&5
[root@guan ~]# read -u5
[root@guan ~]# read -u5
[root@guan ~]# read -u5
^C #管道里俩行,读取第三行会停滞管道来并发控制就是先在管道里写入要并发数量的行数
每次read一行后
然后大括号里面的最后一句是向管道里写入一行,只有后台任务执行完了下一个read -u才不会停滞
举个例子3条任务,并发数量为2,一开始管道里写入2行
然后下面代码
mkfifo test_fifo
exec 5<>test_fifo
rm -f test_fifo
seq 2>&5
for i in {1..3};do
read -u5
{
echo $i;sleep 2; #需要并发的内容统一写在大括号里
echo >&5
}&
done
wait脑补下执行过程,进入循环中:
第一次read(管道里有2行)不会被停滞,管道剩下1行,大括号里的所有代码放在后台(一个后台并发)
第二次read(管道里有1行)不会被停滞,管道剩下0行,大括号里的所有代码放在后台(俩个后台并发)
第三次read(管道里有0行),会被停滞,只有等一个后台执行完了(后台里最后一句)向管道里写入了一个空行,此次的read才会退出停滞状态后面的代码才能继续执行
然后循环结束后最后还有第三次的后台(此处不一定只有第三次的后台,可能第二次后台也没执行完),此处写个wait等待最后剩下的后台完成即可
然后下面是完整的例子
[root@guan ~]# cat -n test.sh
1 #!/bin/bash
2
3 trap 'exec 5>&-;exec 5<&-;exit 0' 2 #捕捉中断信号2(ctrl+C)关闭fd5的意思,善后工作
4
5 max_process=$1
6
7 pipe=`mktemp -u tmp.XXXX`
8 mkfifo $pipe
9 exec 5<>$pipe #这个数值不是0,1,2就行,范围是3-$((`ulimit -u`-1))
10 rm -f $pipe
11
12 seq $max_process>&5 #写入并发数量的行
13
14 start=`date +%s`
15 for i in {1..10};do
16 read -u5
17 {
18 echo $i;sleep 2;
19 echo >&5
20 }&
21 done
22 wait
23 echo 'Time:' "$((`date +%s`-start))"
24
25 exec 5>&-;exec 5<&- #关闭文件操作符必须分开写
[root@guan ~]# sh test.sh 2
1
2
3
4
5
6
7
8
9
10
Time: 10
[root@guan ~]# sh test.sh 9
1
2
4
6
7
9
8
5
3
10
Time: 4
[root@guan ~]#