运维笔记
安全攻防
奇淫技巧
探知未来
赏金猎人
Incipience
Middleware
Kubernetes
Databases
Monitoring
Virtualization
2月18日 · 2026年
《构建高性能 K8s 算力池,榨干大模型生产力》
InfiniBand
Kubernetes
RDMA
2
0
每一毫秒的GPU空转,都是百万算力的无声流逝 在大模型训练中,有一个让所…
1月10日 · 2026年
《大模型全链路工作流编排》
Kubernetes
大模型
2
0
在 2026 年的 AI 工程化领域,构建一个大模型应用早已不再是单纯的…
12月2日 · 2025年
《云原生推理工程化的灵魂》
KServe
7
0
1. 引言 随着大语言模型 (LLM) 的爆发式增长,企业如何高效、低成…
10月11日 · 2025年
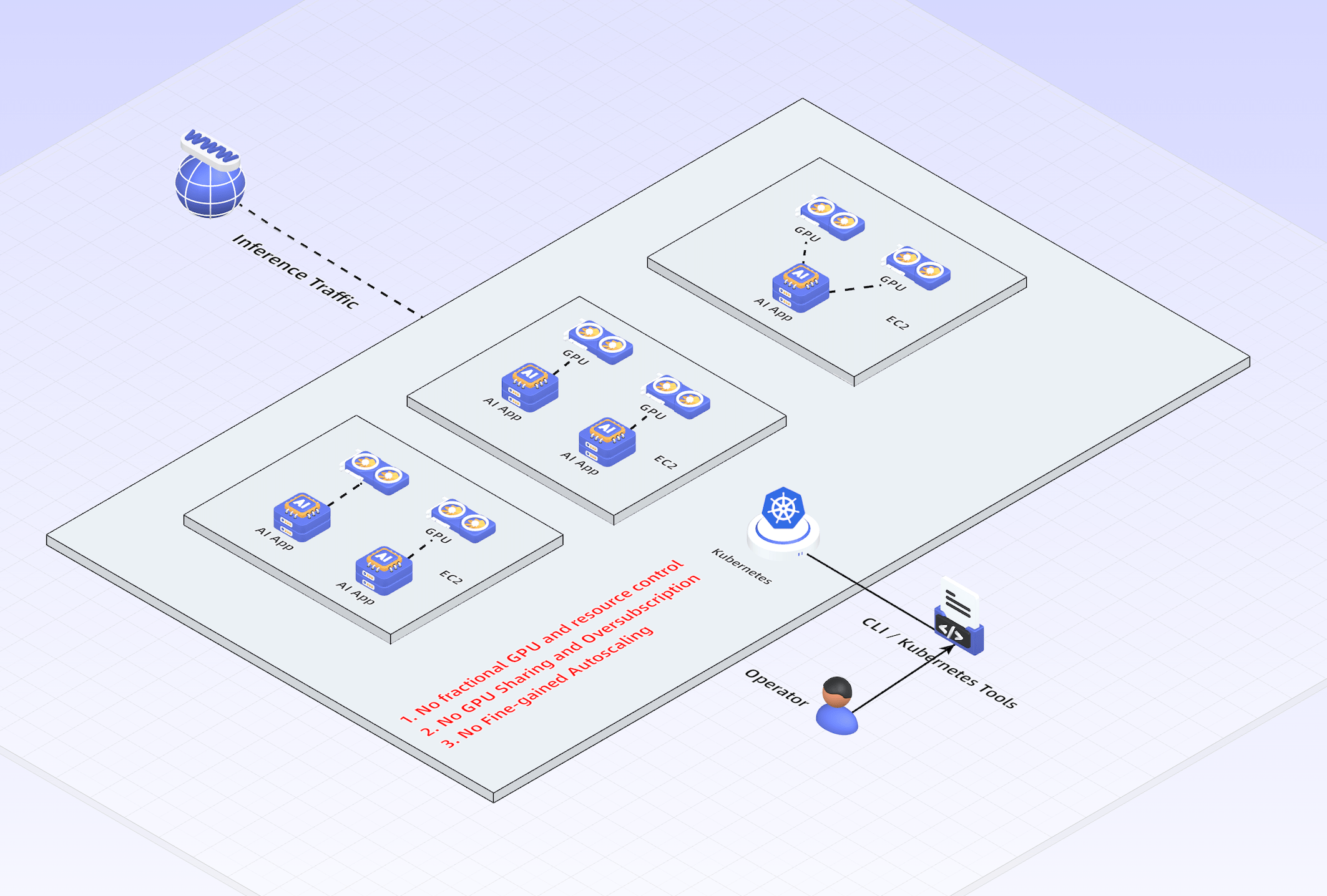
《30% 到 90%:K8s GPU 共享架构演进》
GPU
Kubernetes
1
0
别再为了一个轻量级 API 烧掉整张 A100,那样你的 CFO 会哭的…
7月30日 · 2025年
《大模型推理 OOM 与延迟优化指南》
KEDA
Kubernetes
大模型
1
0
随着大模型(LLM)在企业业务中的普及,如何高效、稳定地部署推理服务成为…
5月5日 · 2025年
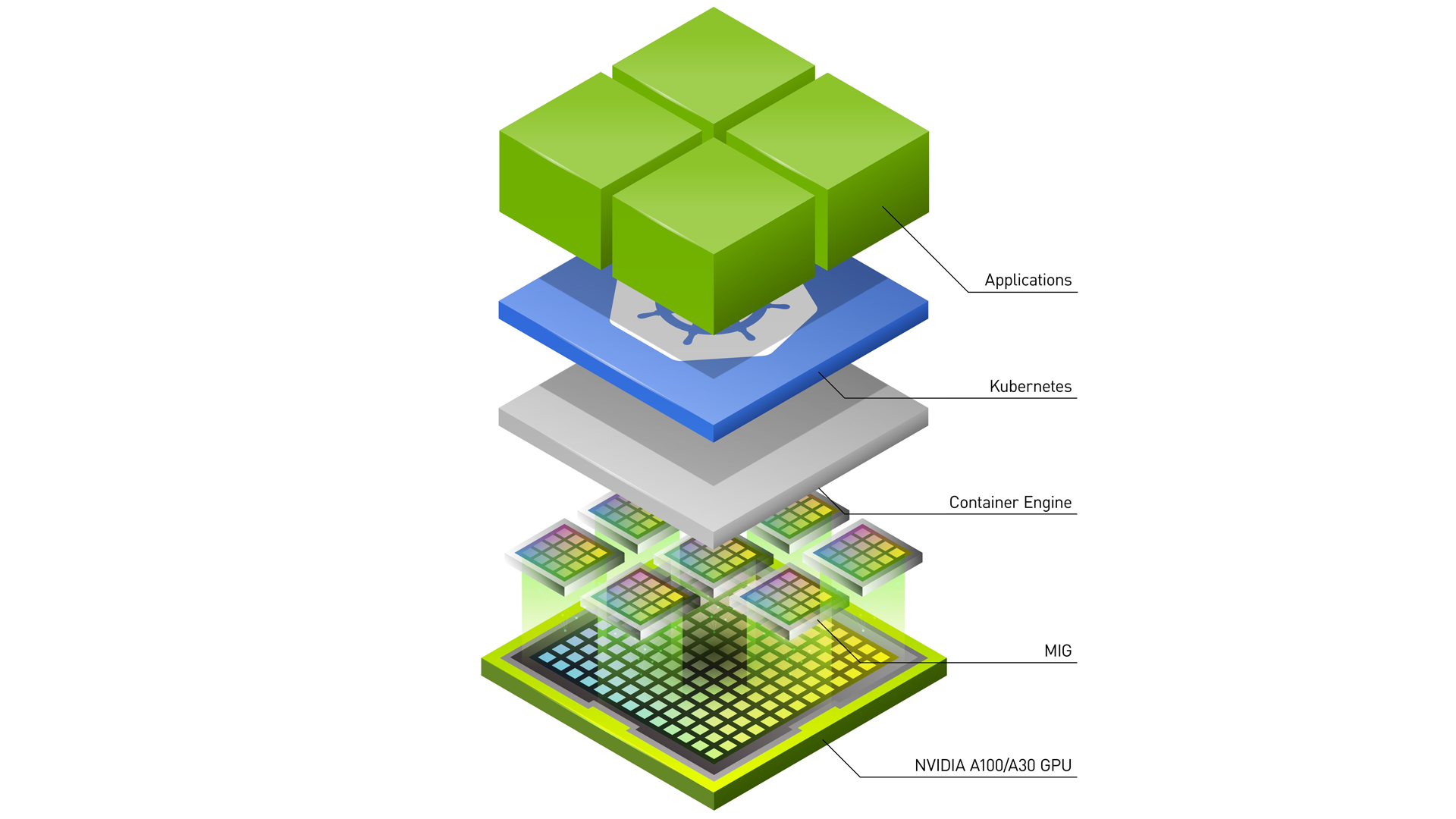
《算力治理:K8s GPU 切分技术栈全景拆解》
GPU
Kubernetes
MIG
vGPU
4
0
“我们 8 张 A100,跑模型 GPU 利用率死活上不去,一直在 30…
3月12日 · 2025年
《算力平权:K8s 打造芯片无关 AI 底座》
k8s
volcano
异构算力
21
0
告别显卡“绑架”,让算力真正为业务所用 在AI算力军备竞赛愈演愈烈的今天…
1月29日 · 2025年
《算法是门脸,工程是命门》
AI
GPU
大模型
12
0
为什么你的大模型训练总是卡在“等待资源”?为什么GPU买了一堆,利用率却…
11月27日 · 2024年
《从0到1搭建K8s GPU调度平台》
GPU
Kubernetes
16
0
别再让你的GPU“睡大觉”了,一套完整的调度平台能让算力利用率翻倍。“我…
9月15日 · 2024年
《AI 基建内功:重构大模型底座》
GPU
1
0
大模型训练一般都是用单机 8 卡 GPU 主机组成集群,机型包括 8*{…
1