序、为何需要存储卷
容器部署过程中一般有以下三种数据:
- 启动时需要的初始数据,可以是配置文件
- 启动过程中产生的临时数据,该临时数据需要多个容器间共享
- 启动过程中产生的持久化数据
以上三种数据都不希望在容器重启时就消失,存储卷由此而来,它可以根据不同场景提供不同类型的存储能力。
各类卷:

- spec.volumes:通过此字段提供指定的存储卷
- spec.containers.volumeMounts:通过此字段将存储卷挂接到容器中
一、普通存储卷的用法
容器启动时依赖数据
1. ConfigMap
上图也说了它是在容器启动的时候以来的数据来源
示例:
# 1.创建configmap预制数据卷
$ cat >> configmap.yaml << EOF
apiVersion: v1
data:
guomaoqiu: hello-world
kind: ConfigMap
metadata:
name: test
EOF
$ kubectl create -f configmap.yaml
configmap/test created
# 2. 创建pod来使用这个configmap
# 这里我创建了一个nginx pod 让他启动是挂载这个数据
$ cat nginx-deployment.yaml
......
......
spec:
containers:
- image: nginx
name: nginx
resources: {}
volumeMounts:
- name: test
mountPath: /tmp # 挂载点
volumes:
- name: test
configMap:
name: test # ConfigMap name
defaultMode: 420 # 指定挂载到pod文件的权限
......
......
# 3.检查数据是否挂载进pod
$kubectl exec nginx-7d8bb9c4fc-bxxkt -- ls /tmp
guomaoqiu
$ kubectl exec nginx-7d8bb9c4fc-bxxkt -- cat /tmp/guomaoqiu
hello-world $
# 以上可以看到将configmap的key作为了文件名,将value作为了文件的内容。
# 他的作用也就是允许您将配置文件从容器镜像中解耦,从而增强容器应用的可移植性
# 更多可查看: https://k8smeetup.github.io/docs/tasks/configure-pod-container/configmap/2. Serect
Secret 是一种包含少量敏感信息例如密码、token 或 key 的对象。这样的信息可能会被放在 Pod spec 中或者镜像中;将其放在一个 secret 对象中可以更好地控制它的用途,并降低意外暴露的风险。
用户可以创建 secret,同时系统也创建了一些 secret。
要使用 secret,pod 需要引用 secret。Pod 可以用两种方式使用 secret:作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里,或者当 kubelet 为 pod 拉取镜像时使用。
示例:
假设有些 pod 需要访问数据库。这些 pod 需要使用的用户名和密码在您本地机器的 ./username.txt 和 ./password.txt 文件里。
# Create files needed for rest of example.
$ echo -n "admin" > ./username.txt
$ echo -n "1f2d1e2e67df" > ./password.txtkubectl create secret 命令将这些文件打包到一个 Secret
$ kubectl create secret generic db-user-pass --from-file=./username.txt --from-file=./password.txt
secret/db-user-pass created
$ kubectl describe secret db-user-pass
Name: db-user-pass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password.txt: 12 bytes
username.txt: 5 bytes
# 默认情况下,get 和 describe 命令都不会显示文件的内容。
# 这是为了防止将 secret 中的内容被意外暴露给从终端日志记录中刻意寻找它们的人。
在 Pod 中使用 Secret 文件
在挂载的 secret volume 的容器内,secret key 将作为文件,并且 secret 的值使用 base-64 解码并存储在这些文件中。这是在上面的示例容器内执行的命令的结果:
$ kubectl exec -it mypod /bin/bash
root@mypod:/# cat /etc/foo/username.txt
admin
root@mypod:/# cat /etc/foo/password.txt
1f2d1e2e67df临时数据存储
1. emptryDir
当 Pod 被分配给节点时,首先创建 emptyDir 卷,并且只要该 Pod 在该节点上运行,该卷就会存在。正如卷的名字所述,它最初是空的。Pod 中的容器可以读取和写入 emptyDir 卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。当出于任何原因从节点中删除 Pod 时,emptyDir 中的数据将被永久删除。
注意:容器崩溃不会从节点
缺省情况下,EmptyDir 是使用主机磁盘进行存储的,也可以设置emptyDir.medium 字段的值为Memory,来提高运行速度,但是这种设置,对该卷的占用会消耗容器的内存份额。
emptyDir 的用法有:
- 暂存空间,例如用于基于磁盘的合并排序
- 用作长时间计算崩溃恢复时的检查点
- Web服务器容器提供数据时,保存内容管理器容器提取的文件
- 可以在同一 Pod 内的不同容器之间共享工作过程中产生的文件。
示例:
apiVersion: v1
kind: Pod
metadata:
name: test-emptydir-pod
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: test-emptydir-pod
volumeMounts:
- mountPath: /temp-data # 挂载点
name: temp-data
volumes:
- name: temp-data
emptyDir: {}创建pod
$ kubectl create -f test-emptydir-pod.yaml
pod/test-emptydir-pod created
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
test-emptydir-pod 1/1 Running 0 18s 10.244.0.23 k8s-m3 <none>此时Emptydir已经创建成功,在宿主机上的访问路径为/var/lib/kubelet/pods//volumes/kubernetes.io~empty-dir/temp-data,如果在此目录中创建删除文件,都将对容器中的/data目录有影响,如果删除Pod,文件将全部删除,即使是在宿主机上创建的文件也是如此,在宿主机上删除容器则k8s会再自动创建一个容器,此时文件仍然存在。
# 获取 pod uid
$ kubectl get pod test-emptydir-pod -o yaml | grep -n uid
11: uid: 3328c9e1-ff8f-11e8-b6d6-00505621dd5b
# 登录到节点k8s-m3 查看
$ ll /var/lib/kubelet/pods/3328c9e1-ff8f-11e8-b6d6-00505621dd5b/volumes/kubernetes.io~empty-dir/
total 0
drwxrwxrwx 2 root root 6 Dec 14 05:58 temp-data2. hostPath
hostPath vol
- 运行的容器需要访问Docker内部结构:使用hostPath映射/var/lib/docker
- 在容器中运行cAdvisor,使用hostPath映射/dev/cgroups
不过,使用这种volume要小心,因为:
- 配置相同的pod(如通过podTemplate创建),可能在不同的Node上表现不同,因为不同节点上映射的文件内容不同
- 当Kubernetes增加了资源敏感的调度程序,hostPath使用的资源不会被计算在内
- 宿主机下创建的目录只有root有写权限。你需要让你的程序运行在privileged container上,或者修改宿主机上的文件权限。
示例:
假设我们在创建docker镜像的时候忘记了更改容器中的时区文件;这时候想把宿主机的/usr/share/zoneinfo/Asia/Shanghai挂到pod中的容器内(这里为了学习挂载方式,暂且不谈不同系统或不同宿主机的一些配置或路径)
apiVersion: v1
kind: Pod
metadata:
name: test-emptydir-pod
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: test-emptydir-pod
volumeMounts:
- name: container-time
mountPath: /etc/localtime # 挂载点,container启动后直接挂载覆盖此文件
volumes:
- name: container-time
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai # 挂载时区文件到container中
通过创建pod后登录检查时区正常。
二、持久存储卷的用法
学习持久化存储之前需要学习一下以下概念:
Volume 提供了非常好的数据持久化方案,不过在可管理性上还有不足。
拿前面 AWS EBS 的例子来说,要使用 Volume,Pod 必须事先知道如下信息:
- 当前 Volume 来自 AWS EBS。
- EBS Volume 已经提前创建,并且知道确切的 volume-id。
Pod 通常是由应用的开发人员维护,而 Volume 则通常是由存储系统的管理员维护。开发人员要获得上面的信息:
- 要么询问管理员。
- 要么自己就是管理员。
这样就带来一个管理上的问题:应用开发人员和系统管理员的职责耦合在一起了。如果系统规模较小或者对于开发环境这样的情况还可以接受。但当集群规模变大,特别是对于生成环境,考虑到效率和安全性,这就成了必须要解决的问题。
Kubernetes 给出的解决方案是 PersistentVolume 和 PersistentVolumeClaim。
PersistentVolume (PV) 是外部存储系统中的一块存储空间,由管理员创建和维护。与 Volume 一样,PV 具有持久性,生命周期独立于 Pod。
PersistentVolumeClaim (PVC) 是对 PV 的申请 (Claim)。PVC 通常由普通用户创建和维护。需要为 Pod 分配存储资源时,用户可以创建一个 PVC,指明存储资源的容量大小和访问模式(比如只读)等信息,Kubernetes 会查找并提供满足条件的 PV。
有了 PersistentVolumeClaim,用户只需要告诉 Kubernetes 需要什么样的存储资源,而不必关心真正的空间从哪里分配,如何访问等底层细节信息。这些 Storage Provider 的底层信息交给管理员来处理,只有管理员才应该关心创建 PersistentVolume 的细节信息。
Kubernetes 支持多种类型的 PersistentVolume,比如 AWS EBS、Ceph、NFS 等,完整列表请参考 https://kubernetes.io/docs/concepts/storage/persistent-volumes/#types-of-persistent-volumes
主要包括:NFS/GlusterFS/CephFS/AWS/GCE等等
作为一个容器集群,支持网络存储自然是重中之重了,Kubernetes支持为数众多的云提供商和网络存储方案。
不同公司选择的方案也是不相同。
下节我用 NFS 来体会它存储的使用方法。
NFS
1. 在NFS存储的服务器创建存储目录:
# 这里先创建三个共享目录稍后会用到.
$ mkdir /{nfs_data_1,nfs_data_2,nfs_data_3}2. 安装nfs:
$ yum -y install nfs-utils rpcbind3. 写入配置
$ echo "/nfs_data_1 *(rw,sync,no_subtree_check,no_root_squash)" > /etc/exports
$ echo "/nfs_data_2 *(rw,sync,no_subtree_check,no_root_squash)" >> /etc/exports
$ echo "/nfs_data_3 *(rw,sync,no_subtree_check,no_root_squash)" >> /etc/exports4. 重启nfs服务验证
$ systemctl restart nfs-server
$ showmount -e 192.168.56.113 # NFS Server
Export list for 192.168.56.113:
/nfs_data_3 *
/nfs_data_2 *
/nfs_data_1 *
# nfs安装并且共享目录已经创建完毕NFS作为普通存储卷
在Kubernetes中,可以通过nfs类型的存储卷将现有的NFS(网络文件系统)到的挂接到Pod中。在移除Pod时,NFS存储卷中的内容被不会被删除,只是将存储卷卸载而已。这意味着在NFS存储卷总可以预先填充数据,并且可以在Pod之间共享数据。NFS可以被同时挂接到多个Pod中,并能同时进行写入。需要注意的是:在使用nfs存储卷之前,必须已正确部署和运行NFS服务器,并已经设置了共享目录。
创建一个pod,让其挂载上面创建的共享目录
$ cat >> nfs-busybox << EOF
apiVersion: v1
kind: Pod
metadata:
name: nfs-busybox-pod
spec:
containers:
- name: nfs-busybox-pod
image: busybox
imagePullPolicy: IfNotPresent
command:
- "/bin/sh"
args:
- "-c"
- "touch /mnt/SUCCESS && exit 0 || exit 1"
volumeMounts:
- name: nfs-busybox-storage
mountPath: "/mnt"
restartPolicy: "Never"
volumes:
- name: nfs-busybox-storage
nfs:
path: /nfs_data_1 # NFS 共享目录
server: 192.168.56.113 # NFS Server
EOF启动POD,一会儿POD就是completed状态,说明执行完毕。
$ kubectl apply -f nfs-busybox.yaml
pod/nfs-busybox-pod created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nfs-busybox-pod 0/1 Completed 0 7s我们去NFS Server共享目录查看有没有SUCCESS文件。
$ ls /nfs_data_1/
SUCCESS说明当NFS作为普通存储卷时我们挂载到pod容器中产生数据将会保存到这个存储卷当中,并且删除pod不会影响数据。
如何基于NFS文件系统创建持久化存储?
Provisioning: PV的预制创建有两种模式:静态和动态供给模式,他们的含义是:
静态供给模式: 需要先手动创建PV, 然后通过 PVC 申请 PV 并在 Pod 中使用,这种方式叫做静态供给(Static Provision)。动态供给模式: 只需要创建PVC,系统根据PVC创建PV, 如果没有满足 PVC 条件的 PV,会动态创建 PV。相比静态供给,动态供给(Dynamical Provision)有明显的优势:不需要提前创建 PV,减少了管理员的工作量,效率高.
动态供给是通过 StorageClass 实现的,StorageClass 定义了如何创建 PV。
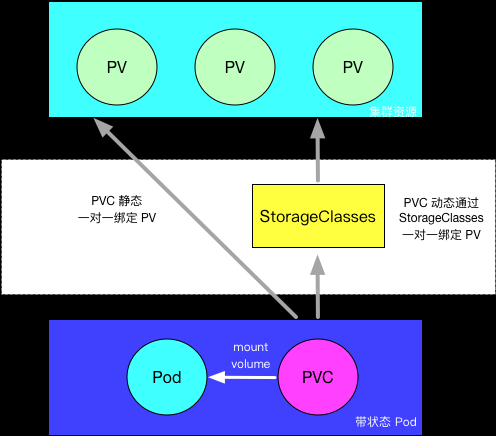
下面就分别实践这两种模式的创建跟使用:
NFS作为静态供给模式持久化存储卷
手动创建PV--->手动创建PVC--->POD挂载使用
1. 创建PV
$ cat >> nfs-test-pv.yaml << EOF
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-test-pv
namespace: default
labels:
app: nfs-test-pv
spec:
capacity:
storage: 5Gi # 指定PV容量为5G
accessModes:
- ReadWriteOnce # 指定访问模式为 ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle # 指定当 PV 的回收策略为 Recycle
storageClassName: nfs # 定 PV 的 class 为 nfs。相当于为 PV 设置了一个分类,PVC 可以指定 class 申请相应 class 的 PV。
nfs:
path: /nfs_data_2 # 指定 PV 在 NFS 服务器上对应的目录
server: 192.168.56.113 # NFS Server地址
EOF
STATUS 为 Available,表示 nfs-test-pv 就绪,可以被 PVC 申请。
接下来创建 PVC nfs-test-pv-claim:
2. 创建PVC
$ cat >> nfs-test-pv-claim.yaml << EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-test-pv-claim
namespace: default
spec:
accessModes: # 存储访问模式,此能力依赖存储厂商能力
- ReadWriteOnce
resources:
requests:
storage: 2Gi # 请求获得的pvc存储大小
storageClassName: nfs
EOF
从 kubectl get pvc 和 kubectl get pv 的输出可以看到 nfs-test-pv-claim 已经 Bound 到 nfs-test-pv,申请成功。
接下来就可以在 Pod 中使用存储了:
3. 创建Pod
$ cat >> nfs-test-pod.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: nfs-test-pod
spec:
containers:
- name: nfs-test-pod
image: busybox
args:
- /bin/sh
- -c
- sleep 30000
volumeMounts:
- mountPath: "/nfs-data"
name: nfs-data
volumes:
- name: nfs-data
persistentVolumeClaim:
claimName: nfs-test-pv-claim
EOF与使用普通 Volume 的格式类似,在 volumes 中通过 persistentVolumeClaim 指定使用 nfs-test-pv-claim 申请的 Volume。

验证 PV 是否可用:
$ kubectl exec nfs-test-pod touch /nfs-data/SUCCESS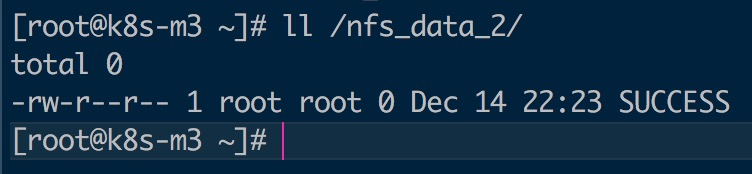
可见,在 Pod 中创建的文件 /nfs-data/SUCCESS 确实已经保存到了 NFS 服务器目录 /nfs_data_2/中。
如果不再需要使用 PV,可用删除 PVC 回收 PV:
4. 回收PVC
持久化卷声明的保护
PVC 保护的目的是确保由 pod 正在使用的 PVC 不会从系统中移除,因为如果被移除的话可能会导致数据丢失。
注意:当 pod 状态为 Pending 并且 pod 已经分配给节点或 pod 为 Running 状态时,PVC 处于活动状态。
当启用PVC保护功能时,如果用户删除了一个 pod 正在使用的 PVC,则该 PVC 不会被立即删除。PVC 的删除将被推迟,直到 PVC 不再被任何 pod 使用。
您可以看到,当我直接删除上面POD正在使用的PVC时命令直接hang住了,此时虽然为 Teminatiing,但PVC 受到保护,Finalizers 列表中包含 kubernetes.io/pvc-protection:
$ kubectl delete pvc nfs-test-pv-claim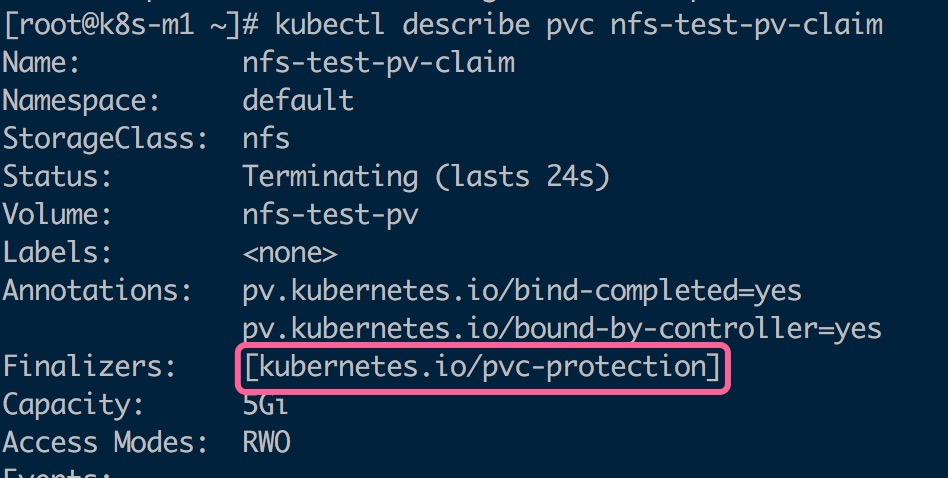
等待 pod 状态变为 Terminated(删除 pod 或者等到它结束),然后检查,确认 PVC 被移除。
反之,如果一个PVC没有被pod使用则可以直接删除。
用户用完 volume 后,可以从允许回收资源的 API 中删除 PVC 对象。PersistentVolume 的回收策略告诉集群在存储卷声明释放后应如何处理该卷。目前,volume 的处理策略有:
- Retain,不清理, 保留 Volume(需要手动清理)
- Recycle,删除数据,即 rm -rf /thevolume/*(只有 NFS 和 HostPath 支持)
- Delete,删除存储资源,比如删除 AWS EBS 卷(只有 AWS EBS, GCE PD, Azure Disk 和 Cinder 支持)
OK 以上是NFS创建静态模式创建PVC,以及PVC跟POD生命周期的一些实践,下面实践动态模式
NFS作为动态持久化存储卷
利用NFS client provisioner动态提供Kubernetes后端存储卷
想要动态生成PV,需要运行一个NFS-Provisioner服务,将已配置好的NFS系统相关参数录入,并向用户提供创建PV的服务。官方推荐使用Deployment运行一个replica来实现,当然也可以使用Daemonset等其他方式,这些都在官方文档中提供了。
前提条件是有已经安装好的NFS服务器,并且NFS服务器与Kubernetes的Slave节点都能网络连通。 所有下文用到的文件来自于git clone https://github.com/kubernetes-incubator/external-storage.git 的nfs-client目录
nfs-client-provisioner 是一个Kubernetes的简易NFS的外部provisioner,本身不提供NFS,需要现有的NFS服务器提供存储
- PV以
${namespace}-${pvcName}-${pvName}的命名格式提供(在NFS服务器上) - PV回收的时候以
archieved-${namespace}-${pvcName}-${pvName}的命名格式(在NFS服务器上)
1. 获取nfs-client-provisioner配置文件
$ git clone https://github.com/kubernetes-incubator/external-storage.git2. 安装部署:
1. 修改deployment文件并部署 deploy/deployment.yaml
需要修改的地方只有NFS服务器所在的IP地址(192.168.56.113),以及NFS服务器共享的路径(/nfs_data_3),两处都需要修改为你实际的NFS服务器和共享目录
$ cat deploy/deployment.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: quay.io/external_storage/nfs-client-provisioner:latest
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: fuseim.pri/ifs
- name: NFS_SERVER
value: 192.168.56.113
- name: NFS_PATH
value: /nfs_data_3
volumes:
- name: nfs-client-root
nfs:
server: 192.168.56.113
path: /nfs_data_3
$ kubectl apply -f deploy/deployment.yaml # 执行部署
serviceaccount/nfs-client-provisioner created
deployment.extensions/nfs-client-provisioner created2. 修改StorageClass文件并部署 deploy/class.yaml
此处可以不修改,或者修改provisioner的名字,需要与上面的deployment的PROVISIONER_NAME名字一致。
$ cat deploy/class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
provisioner: fuseim.pri/ifs # or choose another name, must match deployment's env PROVISIONER_NAME'
parameters:
archiveOnDelete: "false"
# 执行部署
$ kubectl apply -f deploy/class.yaml
storageclass.storage.k8s.io/managed-nfs-storage created
# 查看StorageClass
$ kubectl get sc
NAME PROVISIONER AGE
managed-nfs-storage fuseim.pri/ifs 16m
# 设置这个managed-nfs-storage名字的SC为Kubernetes的默认存储后端
$ kubectl patch storageclass managed-nfs-storage -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
$ kubectl get sc
NAME PROVISIONER AGE
managed-nfs-storage (default) fuseim.pri/ifs 19m3. 授权
如果您的集群启用了RBAC,或者您正在运行OpenShift,则必须授权provisioner。 如果你在非默认的“default”名称空间/项目之外部署,可以编辑deploy/rbac.yaml或编辑`oadm policy“指令。
如果启用了RBAC
需要执行如下的命令来授权。
$ cat deploy/rbac.yaml
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
$ kubectl create -f deploy/rbac.yaml
clusterrole.rbac.authorization.k8s.io/nfs-client-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/run-nfs-client-provisioner created
role.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
4. 执行部署:
测试创建PVC
$ cat deploy/test-claim.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
annotations:
volume.beta.kubernetes.io/storage-class: "managed-nfs-storage"
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Mi
$ kubectl create -f deploy/test-claim.yaml
persistentvolumeclaim/test-claim created
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-137f0450-0048-11e9-af7a-00505621dd5b 1Mi RWX Delete Bound default/test-claim managed-nfs-storage 9m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/test-claim Bound pvc-137f0450-0048-11e9-af7a-00505621dd5b 1Mi RWX managed-nfs-storage 9m
# 以上可以看到我们的pvc已经申请成功,等待POD挂载使用测试创建POD :
POD文件如下,作用就是在test-claim的PV里touch一个SUCCESS文件。
$ cat deploy/test-pod.yaml
kind: Pod
apiVersion: v1
metadata:
name: test-pod
spec:
containers:
- name: test-pod
image: gcr.io/google_containers/busybox:1.24
command:
- "/bin/sh"
args:
- "-c"
- "touch /mnt/SUCCESS && exit 0 || exit 1"
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: test-claim
$ kubectl create -f deploy/test-pod.yaml
pod/test-pod created
# 启动POD,一会儿POD就是completed状态,说明执行完毕。
$ kubectl get pod | grep test-pod
NAME READY STATUS RESTARTS AGE
test-pod 0/1 Completed 0 18s
在NFS服务器上的共享目录下的卷子目录中检查创建的NFS PV卷下是否有”SUCCESS” 文件。

以上,说明我们部署正常,并且可以通过动态分配NFS的持久共享卷 。
参考文献
https://kubernetes.io/docs/concepts/configuration/secret/
https://k8smeetup.github.io/docs/concepts/storage/persistent-volumes/#回收-1
https://k8smeetup.github.io/docs/tasks/administer-cluster/pvc-protection/#lichuqiang
https://jimmysong.io/kubernetes-handbook/practice/using-nfs-for-persistent-storage.html
赞,总结得非常好